de BAG v1_1 WFS service is gewijzigd na aanleiding van een aantal verzoeken vanuit onze afnemers.
De wijzigingen hebben betrekking op het gebruik van het featureID.
De featureID’s hebben een prefix gekregen met ‘bag:’. Hiervoor is gekozen omdat er problemen waren met het aanroepen van features die een ID hebben met voorloopnullen.
Helaas is de performance van de WFS query met het FES filter dramatisch maar daarvan zijn jullie al op de hoogte.
Bij MapServer werken ook WFS queries met matchcase=“false” niet. Dat is al een vrij oude bug maar nog steeds niet opgelost. Het geeft wel een beetje te denken wat doorontwikkeling betreft t.o.v. Geoserver.
Jullie hebben zo je redenen wat betreft stabiliteit en geheugengebruik om te kiezen voor MapServer ipv Geoserver maar MapServer heeft ook zo zijn nadelen (ook geen CQL_FILTER).
Hopelijk komen er niet nog meer nadelen naar boven.
Hoi @rli, nee daar waren we (ik) niet zo van op de hoogte. Wij zien namelijk met “simpele” FES filters requesten dat mapserver een aanzienlijk stuk sneller is, in bepaalde gevallen een factor 10x. Ik geef toe dat onze testen zich richten op 80% van wat ons verkeer is en dat we met “complexere” FES filters testen geen 100% dekking kunnen creëren op wat allemaal op ons kan worden afgevuurd.
Komt vanuit de mapserver stack terug binnen <50ms en vanuit de geoserver stack boven de 400>ms.
Graag zou ik voorbeelden zien van requesten met een FES filters waarin de performance te wensen overlaat? Mogelijk dat we naar de onderliggende queries kunnen kijken. Mogelijk iets met de tijd van de dag? @rli zou jij die kunnen posten?
M.b.t. onze redenen hoop ik dat jij die kan begrijpen waarom wij (PDOK) deze weg hebben (moeten) nemen. Het klopt Mapserver heeft issues net zoals Geoserver en vrijwel ieder stukje software. Hoewel we CQL_FILTER zien als iets “vendor specific” en het creeeren (wat nu de situatie is) van een “vendor lock-in” verre van wenselijk is voor een open data platform.
Hier zit ook de “uitdaging”, een platform bouwen wat werkt voor zoveel mogelijk mensen/use-cases. Hierin kunnen we helaas nooit iedereen 100% facilitieren maar hopen we mensen wel zo veel en goed mogelijk op weg te kunnen helpen met hoe we de data in PDOK “presenteren”. Dat hier dan soms iets buitenboord valt is dan soms een gegeven. Dat gezegd hebben zijn wij altijd bereid om mee te denken over mogelijk alternatieve of andere oplossingen.
Feit blijft dat voor het bouwen van oplossingen tegen PDOK (of iedere NSDI of ander data platform) dit niet een “one-way street” is. Platformen zijn dynamisch (WFS → OGC OAF, TMS → WMTS), dat mag dan ook verwacht worden voor de applicaties die daar mee interface.
Dat is iets waar wij natuurlijk geen garanties op kunnen geven.
Het gaat om een WFS query op ResourceId die je in je originele post hebt geplaatst maar dan niet voor ligplaats maar voor verblijfsobject. Die is zeer traag.
De WFS query op identificatie van verblijfsobject en pand is wel snel omdat jullie daar op mijn verzoek een index op hebben gezet.
Echter de WFS query op pandidentificatie van verblijfsobject is nog traag omdat daar nog geen index op staat waarschijnlijk. Deze is nodig om te achterhalen welke verblijfsobjecten bij een pand horen:
Wij hebben na aanleiding van jouw vragen de onderliggende queries aangepast voor de https://geodata.nationaalgeoregister.nl/bag/wfs/v1_1. De fes:ResourceId request gaan hiermee voor de verschillende bag objecten nu snel. Wij zien sub 100ms responses hierop.
Voor de pandidentificatie is er een index toegevoegd, hiermee zien wij ook een verbeterde performance.
Ik zie nog andere verschillen met de oude WFS service:
huisnummer was numeriek, maar is nu een string
huisletter en toevoeging geven een leeg element voor NULL waarden. De oude WFS service liet de elementen weg, zoals je in een xml document zou verwachten. Mogelijk is dit een MapServer eigenaardigheid? Dat zou betekenen dat NULL waarden in andere string velden ook problemen geven.
Geen heel schokkende zaken maar wel onverwacht als het niet wordt vermeld in het overzicht met wijzigingen:
De volgende aspecten zijn in deze v1.1 veranderd ten opzicht van de huidige BAG webservices:
Het attribuut ‘actualiteitsdatums’ is komen te vervallen
De voorloopnullen van het BAGID worden niet meer verwijderd
Ieder featuretype bevat een verwijzing naar Linked Data door middel van ‘rdf_seealso’
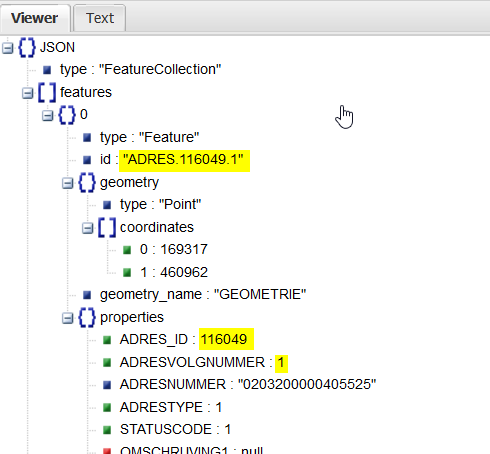
De featureID van een feature is erg belangrijk voor het terug kunnen zoeken via een featureID in het GetFeature request. Ik zie dat bij outputFormat GML wel de featureID wordt meegegeven , maar bij application/json niet.
Dit is superlastig. We werken namelijk niet met GML, maar natuurlijk met json output.
Dus: https://geodata.nationaalgeoregister.nl/bag/wfs/v1_1?request=getfeature&service=wfs&version=2.0.0&typenames=bag:ligplaats&startindex=0&count=1&outputFormat=application/json
Geeft geen featureID, als je outputFormat weg laat dan wel ( dus wel; <bag:verblijfsobject gml:id=“verblijfsobject.0307010000437123”> )
Ook ik vind het echt jammer dat Mapserver nu gebruikt wordt, nu moeten we de WFS van Mapserver, die zich iets ander gedraagt, in onze viewer opnemen. Maar dus die featureID in het resultaat bij JSON is essentieel. Kan die er a.u.b. in ?
Dag Erkan,
Ik neem aan dat dit gaat over het toevoegen van de featureID in de json ouputFormat? Geldt dit ook voor de GetFeatureInfo in een WMS aanroep?
Peter-Paul
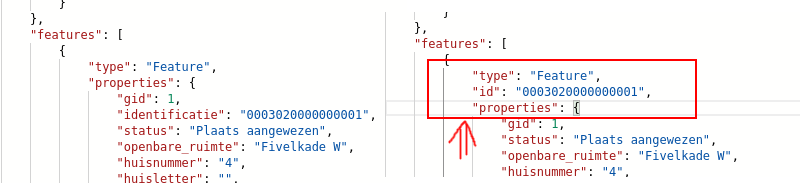
Het ontbreken van het id in de application/json responses hebben wij over het hoofd gezien dit willen we graag herstellen gezien wij ook van mening zijn dat dit de correct oplossing is.
Wat er voor de het response dan ‘mogelijk’ zal veranderen is dat het veld features>properties>identificatie naar features>id ‘verplaatst’.
Is dit in lijn met de verwachting die er is van jouw kant?
Tevens hebben wij het gevoel dat er mogelijk meer dingen spelen gezien de posts. Zoals in eerder posts naar andere gebruikers is aangegeven, willen wij graag met onze klanten meedenken.
Bij deze opmerking willen we graag van jou weten waarom dit jammer is?
Welke gedrag heeft Mapserver ten opzichte van wat jij zou verwachten? Bedoel je bijvoorbeeld het CQL_FILTER?
Voor ons (PDOK) is het namelijk lastig om dit soort informatie te achterhalen, dit soort feedback helpt ons. En dan graag met voorbeelden/linkjes naar jullie implementaties/enz… zodat we van te voren mogelijk afwijkend gedrag kunnen constateren.
Deze proberen we dan ook zoveel mogelijk in lijn te trekken met de WFS json output.
@geonovation zoals eerder in dit topic is aangegeven. Dat services “moeten” wijzigen (door technisch of functioneel redenen) is een gegeven daar proberen we dan ook zo goed mogelijk mee om te gaan en is feedback van onze gebruiker belangrijk. We krijgen het gevoel dat dit door nu niet zo ervaren is door jullie klopt dat? En wat zou er volgens jou dan beter kunnen?
Dag Wouter en Erkan,
De featureId is belangrijk, zodat je weet hoe je bij elk object kunt komen ( als het ware de primary key van een feature, zodat een feature is op te halen met featureID= ). Doordat identificatie niet meer in de properties zit, verwacht ik dat veel afnemers die gaan missen. Het lijkt dubbelop om de identificatie als feature.id op te nemen en als feature.properties.identificatie, maar naar mijn mening is het dat niet. Identifcatie is namelijk een belangrijk attribuut om te tonen. Daarom moet dat ook blijven bij identificatie.
Wat we wel eens tegenkomen is dat een feature niet een eenduidige sleutel heeft. Dus 2 attrributen ( een id en volgnummer) wat het object uniek maakt. Dit is wellicht een niet veel voorkomend voorbeeld, maar het geeft wel aan dat we graag en een feature.id willen hebben en een attribuut wordt ook getoond kan worden.
Ik zie dat deze herstelactie voor het Id-veld in JSON nog niet is gedaan.
Ook wij hebben dat nodig!
Dit geldt voor de BAG WFS V1.1 maar ook voor Kadastrale WFS v4.0.
Kan dit z.s.m. worden gedaan i.v.m. met de uitfasering van de oude services?
Dat is hoe de applicatie nu werkt, die vraagt de ingestelde properties op.
Het zou niet nodig moeten zijn om “fid” op te geven. De id-property is namelijk geen gewone property en die zie je ook niet binnen de normale properties van JSON resultaat. Id zou altijd in het resultaat moeten zitten,
Misschien is de belangrijkste vraag: als jullie deze property niet weg filteren, werkt het dan. En dan nog graag antwoord op mijn initiele vraag: doen jullie dit om het “rdf_seealso” veld weg te filteren?