Beste allemaal,
Graag zouden wij een aantal data sets die in het Nationaal Georegister te vinden zijn willen downloaden, zodat we altijd een kopie hebben op onze eigen server, voor als de verbinding wegvalt.
Mijn vragen hierover:
- Is dit uberhaupt mogelijk? Hoe dan?
- We zouden graag een keer testen hoe dit werkt. Onze voorkeur heeft deze: http://nationaalgeoregister.nl/geonetwork/srv/dut/catalog.search#/metadata/d18acff6-8287-4239-aada-2ccad1586023?tab=relations. Zou dit ook voor andere -een beperkt aantal- webservices kunnen?
- Hoe zorgen we ervoor dat, als er een nieuwe versie beschikbaar komt, wij hiervan op de hoogte zijn?
Alvast bedankt voor jullie antwoorden
Hoi @GSchaepman1
Ja dat is mogelijk, voor deze dataset is het vrij eenvoudig gezien het 3 featuretypes betreft, met ieder 1 feature betreft. Maar om je vraag beter te kunnen beantwoorden, helpt het om te weten wat jullie ‘eigen’ server is, en wat voor tooling jullie denken te gebruiken/tot beschikking hebben.
In hoofdlijnen zal de workflow iets zijn als (er van uit gaande dat jullie de feature/WFS informatie willen hebben en niet alleen een plaatje/WMS):
-
registreren op de RSS feed van het betreffende metadata record: http://nationaalgeoregister.nl/geonetwork/srv/dut/rss.search?sortBy=changeDate&uuid=d18acff6-8287-4239-aada-2ccad1586023 met een (?) RSS feed reader. Zodat wanneer er een nieuwe versie beschikbaar je een signaaltje krijgt om ‘iets’ af te trappen.
-
Vanuit het betreffende metadata record op NGR is te achterhalen wat het service endpoint is: Mapbender - INSPIRE Data Viewer - the Netherlands
-
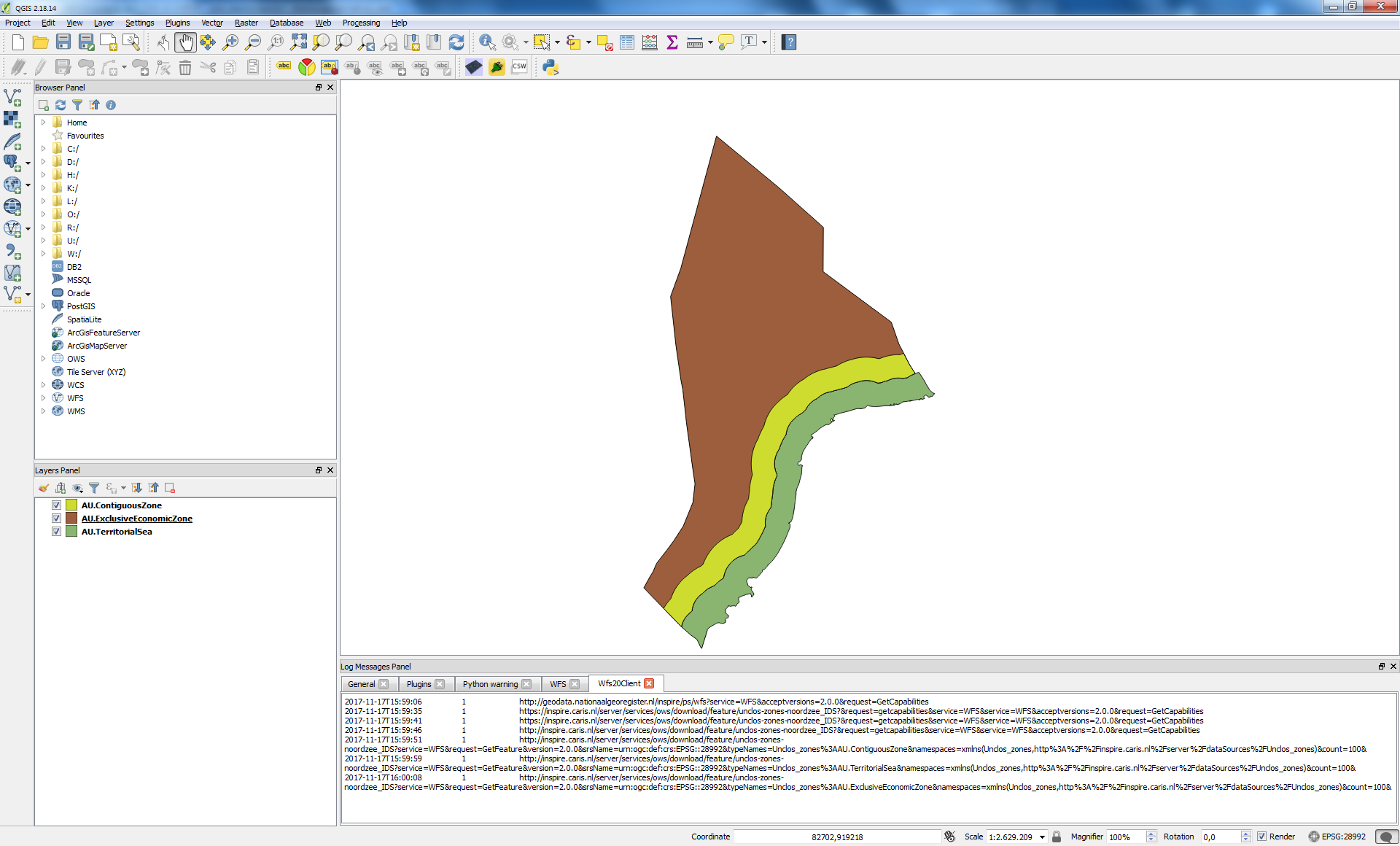
Uit het aanroepen van het Getcapabilities document zijn de aangeboden features te herleiden, in dit geval:
- Unclos_zones:AU.ContiguousZone
- Unclos_zones:AU.TerritorialSea
- Unclos_zones:AU.ExclusiveEconomicZone
-
Ieder featuretype is dan met een getfeature request te bevragen, waarmee alleen features als XML/GML binnen te halen zijn.
-
Deze dienen dan naar jullie server weggeschreven te worden.
Hoe dit technische te realiseren is, dat kan op 1000 en 1 manieren. Waarvan technische kennis, beschikbaar tooling en de hoeveelheid (wenselijke) handmatige werkzaamheden doorslaggevend zullen zijn…
De bovenstaande workflow zou op het meest simpele niveau met een browser + RSS reader en QGIS +
WFS2.0 plugin (Welkom bij het QGIS project!) gerealiseerd kunnen worden, mitst jullie zelf handmatig de RSS feed checken en wanneer er een update is zelf de WFS inladen in QGIS en daar mee wegschreven naar postgis(?)/geopackage
Misschien dat andere nog simpelere/betere alternatieven weten…
Groet,
Wouter
Ha @GSchaepman1, ik sluit me bij @wouter.visscher aan (dank voor je uitvoerige antwoord). Daarnaast zou je ook zelf het initiatief kunnen nemen door dagelijks te pollen welke metadata records die dag gewijzigd zijn (metadata datum > gisteren), of meer exact welke dataset-wijzigingsdatum > gisteren, helaas wordt dit laatste veld niet altijd ingevuld (het is niet verplicht).
Voor het pollen kun je de geonetwork q-service gebruiken, dan wel het atom/opensearch of CSW (http://www.opengeospatial.org/standards/cat) endpoint.
De beschikbare export formaten verschillen een beetje per WFS (diverse organisaties gebruiken diverse WFS producten), je zult echter altijd het GML formaat aantreffen, daarnaast is regelmatig GeoJson, Shape-zip, csv, KML of GeoPackage (SQLite) beschikbaar. Met de GDAL/OGR bibliotheek zijn echter alle formaten relatief eenvoudig om te zetten naar het door jullie gewenste formaat (bv mysql/postgres). Je kunt overigens met ogr2ogr ook rechtstreeks de WFS bevragen en laten weg schrijven naar een database (http://www.gdal.org/drv_wfs.html)
Nog een aanvulling, het product ldproxy (Docker) is in staat om de inhoud van een catalogus te harvesten, en de inhoud van de wfs-endpoints die daarin genoemd worden beschikbaar te stellen middels een rest-api, met een web-crawler als lod-laundromat (GitHub - LOD-Laundromat/LOD-Laundromat: Cleaning other people's dirty data.) zou je op die manier ook alle content kunnen indexeren.
beste @wouter.visscher en @pvgenuchten,
Heel hartelijk dank voor jullie uitgebreide antwoorden. Hier kunnen we zeker verder mee.
Met de GDAL ogr2ogr optie heb ik afgelopen vrijdag al even gestoeid. Dat was inderdaad redelijk eenvoudig. Het nadeel is alleen dat de namen van de layers dan in codetaal zijn opgeslagen en jullie zullen begrijpen dat het niet handig isom elke keer handmatig de namen te moeten aanpassen na een update. Wat dat betreft zou de RSS m.b.v. een GETFEATURE request misschien beter werken.
Werkt die methode overigens ook bij een WMS? De ogr2ogr van GDAL namelijk niet.
@wouter.visscher Onze eigen server is een LINUX server, waarop we zowel een WMS als WFS willen hosten. Weet niet precies wat je met Tooling bedoelt?
Ha Guido, let op, mogelijk lopen 2 zaken door elkaar.
CSW (en RSS) gebruik je om te achterhalen welke datasets als geheel een update hebben gehad.
WFS, SOS en WCS gebruik je om individuele data records van een dataset op te halen. Voor WFS bestaat (vooralsnog*) geen protocol om alleen gewijzigde features op te halen.
WM(T)S is een visualisatie standaard op basis van bitmaps. Je kunt daar in principe geen ruwe data mee opvragen (behalve op een bepaald punt een feature-info uitvoeren).
je zou met de parameter ‘-nln’ een target naam kunnen definieren. (ogr2ogr — GDAL documentation)
met Tooling in de brede zin: geoserver, arcgis, fme, qgis, gdal(ogr2ogr) enz…
Hoi Wouter,
Opnieuw dank voor je tip. Ik ga ermee aan de slag.
We hebben hier op kantoor vele tools tot onze beschikking een ook enkele programmeurs, dus er is veel mogelijk. We hebben onder andere: FME, Global Mapper, ArcGIS, QGIS, MapInfo, GDAL.
We moeten nog een besluit welk Server pakket we gaan gebruiken. Waarschijnlijk beginnen we met GeoServer, om later wellicht ook MapServer te gebruiken.
Met vriendelijke groet,
Guido
Beste @pvgenuchten en @wouter.visscher,
We zijn inmiddels een stuk verder en we hebben veel van jullie adviezen op kunnen volgen. Nogmaals dank voor jullie antwoorden, dat heeft ons de juiste richting gegeven!
We zijn ons daarom thans aan het oriënteren hoe we de metadata (van Web Services en data we dus zelf hosten) het beste in kunnen richten en beschikbaar maken. Onze voorkeur heeft het om een CSW op te richten. Op de lange termijn biedt dit namelijk veel voordelen. Graag zouden we dit met de Open Source GeoNetwork op willen zetten.
Wij hebben hier echter geen ervaring mee. Wat is jullie inschatting? Is het dan haalbaar om het zelf op te zetten? Hoeveel tijd kost het om het pakket van GeoNetwork te leren? Mensen zijn hier over het algemeen wel best handig, kunnen programmeren en pakken nieuwe software snel op. Aan de andere kant hebben we genoeg te doen, dus als het erg veel tijd kost is het misschien beter op zoek te gaan naar een externe partij…
Met vriendelijke groet,
Guido
Ha Guido, GeoNetwork is goed zelf op te zetten, bijvoorbeeld met behulp van de docker variant (Docker) of platform onafhankelijke installer (Download geonetwork-install-3.4.1-0.jar (GeoNetwork - Geographic Metadata Catalog)). echter zodra je GeoNetwork in productie wilt gaan draaien zijn er wat tips die je moet volgen https://geonetwork-opensource.org/manuals/3.4.x/en/maintainer-guide/installing/index.html.
Met de GeoNetwork Gebruikersgroep Nederland en PDOK hebben we de laatste maanden gewerkt aan een nl versie van GeoNetwork, je kunt daar meer over lezen op GitHub - osgeonl/geonetwork-dutch-skin at 3.4.x. Daar is ook een docker variant van op Docker. Op de issue tracker van die repository kun je ook vragen stellen over het draaien van geonetwork in een nl context.
Als alternatief op GeoNetwork zou je kunnen overwegen naar pyCSW te kijken.
Hoi Paul @pvgenuchten ,
Bedankt voor de antwoorden. Alles is te vinden op internet, je moet alleen weten waar  . fijn dat je ons de weg hebt gewezen.
. fijn dat je ons de weg hebt gewezen.
Ik begrijp uit je verhaal dat het opzetten niet zo moeilijk is, maar dat het inrichten van de server en database wat tijd en inzicht kost. Bovendien moeten we daarna nog de metadata er in gaan krijgen natuurlijk. Enig idee hoeveel tijd het bij elkaar kost? We hebben zo’n 70 WFS services.
Verder gaan gewoon alvast beginnen en kijken waar we tegenaan lopen. We houden je op de hoogte.
Groet
Hoeveel tijd je nodig hebt is sterk afhankelijk van wat je wilt bereiken. Ik zou zeggen iets tussen 1 uur en 2 dagen.
Mogelijk is de WFS harvester voor jullie interessant, hiermee kun je metadata laten genereren op basis van een WFS url.
zie Harvesting OGC Services — GeoNetwork opensource v3.12 GeoNetwork Documentation
Merk op dat je een harvester kunt dupliceren (want je moet waarschijnlijk 70 harvesters inrichten). Merk ook op dat er in settings een setting is om harvested metadata achteraf te kunnen muteren.