Het is mijn eerste post hier op GeoForum, dus voor mij best wel spannend. Ik heb een vraagje naar aanleiding van de data stories betreft de CBS linked data. Properties van de kerncijfers wijken en buurten 2016 kon ik vinden op de volgende link https://betalinkeddata.cbs.nl/def/83487NED# Echter informatie over de geometrische grenzen van wijken, buurten of gemeenten kan ik echter niet gemakkelijk vinden.
Er worden wel in de datastories voorbeeldqueries aangekaart wanneer men duidelijk weet wat de gemeente/buurt/wijk is, maar ik zou het juist willen weten waneer men de buurt/wijk/gemeente juist niet kent.
Dus stel ik klik op een pand (BAG) en daarvan wordt bv de geowkt afgeleid en vervolgens kijkt men naar de geowkt van de gemeente/buurt/gemeentegrenzen met bv. geo:sfWithin (echter in de datastories wordt vermeld dat deze functie niet werkt ) om vervolgens te checken bij welke buurt, gemeente of buurt de pand hoort. Weet iemand of dit mogelijk is met CBS data en zo ja, hoe ik dat eventueel zou kunnen bereiken?
Ik weet namelijk niet hoe je de geowkt van de gemeente/buurt/wijk kunt oproepen en of er een andere mogelijkheid bestaat naast geo:sfWithin.
Ik heb eventueel de volgende query uitgeprobeerd om de subclasses van gemeente te verkrijgen, maar dat werkte helaas niet
In je query probeer je subklasses van gemeente op te halen, maar de klasse Gemeente heeft geen subklasses in het model. Zie (http://betalinkeddata.cbs.nl/def/cbs).
Je zou wel de subklasses van de klasse Regio kunnen ophalen met
Hallo @pano ,
Dank je wel voor de uitgebreide query, ik had echter nog een vraag, ik vraag informatie expliciet via the volgende sparql endpoint, https://betalinkeddata.cbs.nl/sparql, maar indien ik informatie wil van verschillende sparql endpoints, kan ik dan gewoon de SERVICE van bv. PDOK en CBS in dezelfde query gebruiken zoals hier beneden en zo ja zijn de variabelen binnen zo { } van een SERVICE point overdraagbaar naar de { } van een andere SERVICE point
select *
where
{
SERVICE <https://betalinkeddata.cbs.nl/sparql>
{
}
SERVICE <https://data.pdok.nl/sparql>
{
}
}
Ik heb de informatie wat betreft geo:sfWithin bij de data story van de gemiddelde woningwaarde in Zoetermeer gevonden. In deze data story wordt er gebruik gemaakt van een blank node i.p.v geo:sfWithin.
Ja, je kunt de SERVICE clauses op die manier gebruiken. Merk op dat als je de query uitvoert op 1 van deze twee endpoints je geen SERVICE clause moet opnemen voor dat endpoint. Je bent daar dan al .
Verder zijn de variabelen in de SERVICE clauses inderdaad beschikbaar buiten de clause, of in andere scopes in je query.
Ik had nog een vraagje, weet je toevallig of de eenheden van de waarden van de properties eveneens bevraagd kunnen worden. Het is mij namelijk gelukt om de waarden van bv. bedrijfsinvesteringen op te vragen. Maar het is niet duidelijk wat de eenheden van deze waarden zijn
Hiermee kun je een dataset langs verschillende dimensies opdelen. 1 manier om dat te doen is om de dataset op te delen in slices. Hiermee kun je voor een set observaties algemene eigenschappen op 1 plaats beheren. Bijvoorbeeld een meeteenheid.
Hallo Pano,
Bedankt voor de uitleg. Ik ben echter helaas niet erg bekend met slices. Ik heb een beetje de documentatie van de Data Structure Definition doorgelezen en vervolgens gekeken naar https://betalinkeddata.cbs.nl/query/83487NED/dsd. Ik snap echter niet waar de obs en de obs:BedrijfsvestigingenTotaal_78_NL00 vandaan komen. Ikzelf gebruik gewoon de prefix def: <http://betalinkeddata.cbs.nl/def/83487NED#> om elementen met een bepaalde predicate te krijgen zoals bv. def:bedrijfsvestigingen_Sbi2008_BedrijfsvestigingenNaarActiviteit_M-nZakelijkeDienstverlening ?bedrijfsvestigingen_Sbi2008_BedrijfsvestigingenNaarActiviteit_M_nZakelijkeDienstverlening
Ik snap dus niet helemaal hoe de PREFIX obs zicht verhoudt ten opzichte van de PREFIX def
en hoe ik gemakkelijk de output van def vervolgens zonodig moet vertalen naar obs om vervolgens de unit ervan te kunnen afleiden.
Het is aan te raden om de RDF Data Cube Vocabulary specificatie goed door te lezen. Onderaan de pagina staat ook een voorbeeld die erg lijkt op hoe deze dataset is opgebouwd.
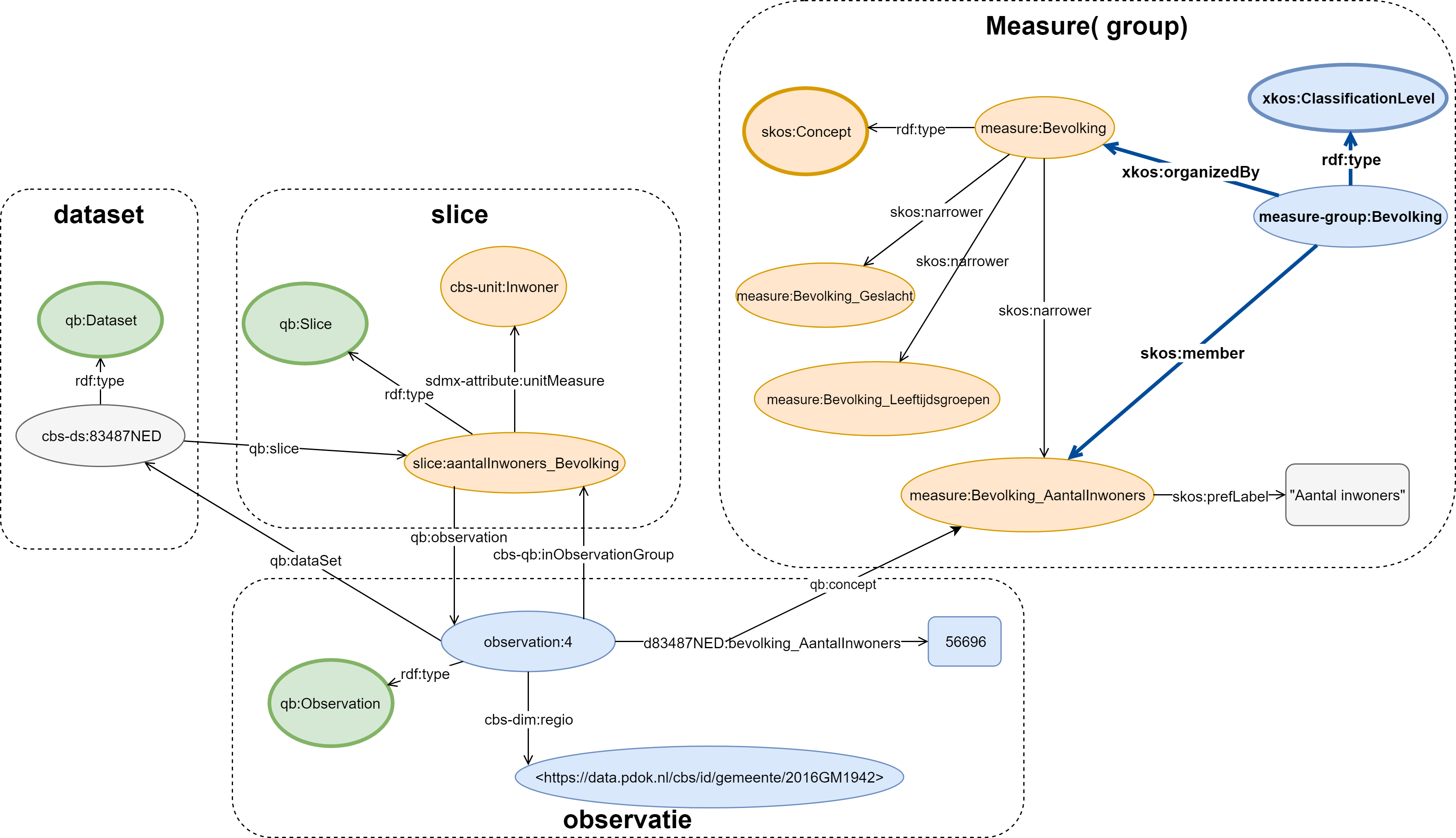
Om je nog wat op weg te helpen is hier een plaat die een overzicht geeft van een (fictieve) observatie en diens relatie tot de dataset, de slice en measures.
 ) om vervolgens te checken bij welke buurt, gemeente of buurt de pand hoort. Weet iemand of dit mogelijk is met CBS data en zo ja, hoe ik dat eventueel zou kunnen bereiken?
) om vervolgens te checken bij welke buurt, gemeente of buurt de pand hoort. Weet iemand of dit mogelijk is met CBS data en zo ja, hoe ik dat eventueel zou kunnen bereiken? .
.