Voor een opdracht wil ik graag vespreiding van doelsoorten over elkaar leggen door een MCA. Ik wil de lagen over elkaar leggen zodat ik kan zien waar de verschillende doelsoorten te samen voorkomen. Dit wil ik doen door elke laag een getal te geven en dan bij elkaar op te tellen zodat hoe hoger het getal hoe hoger de prioriteit hier is. Maar ik krijg dit niet goed voor elkaar…
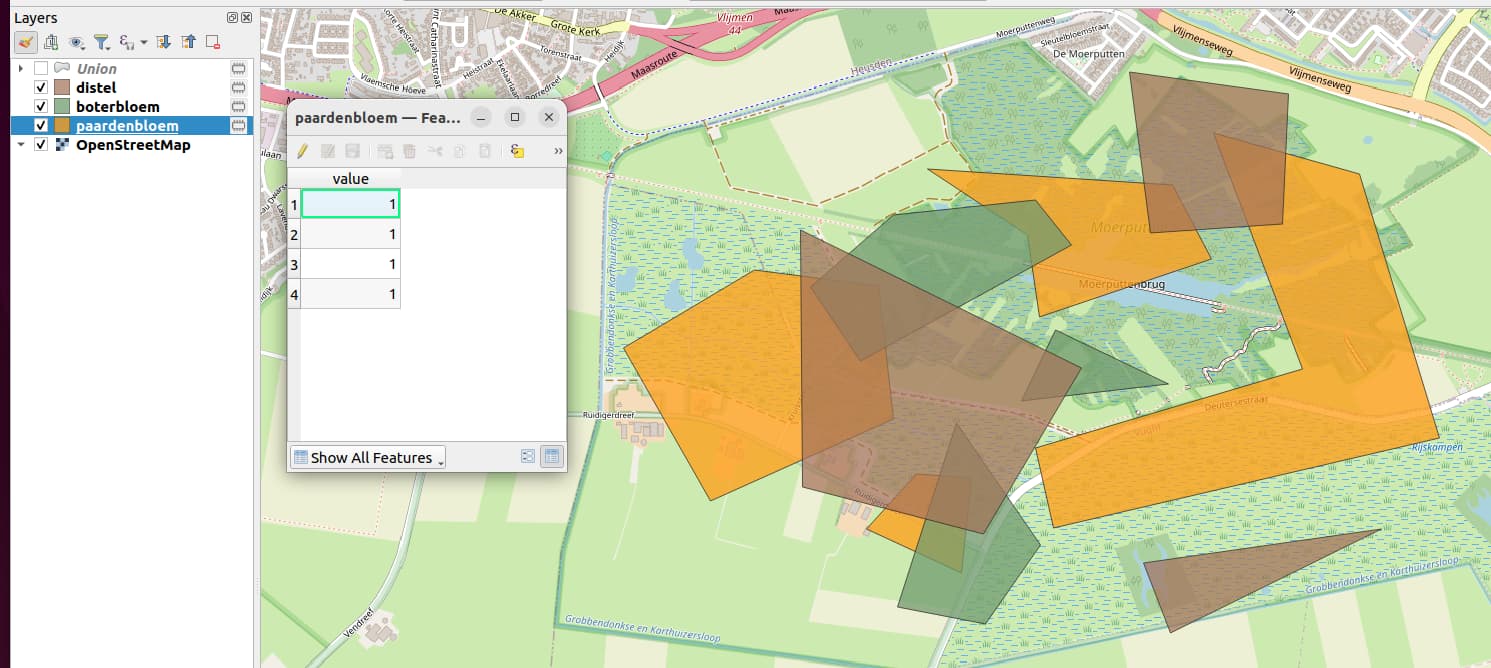
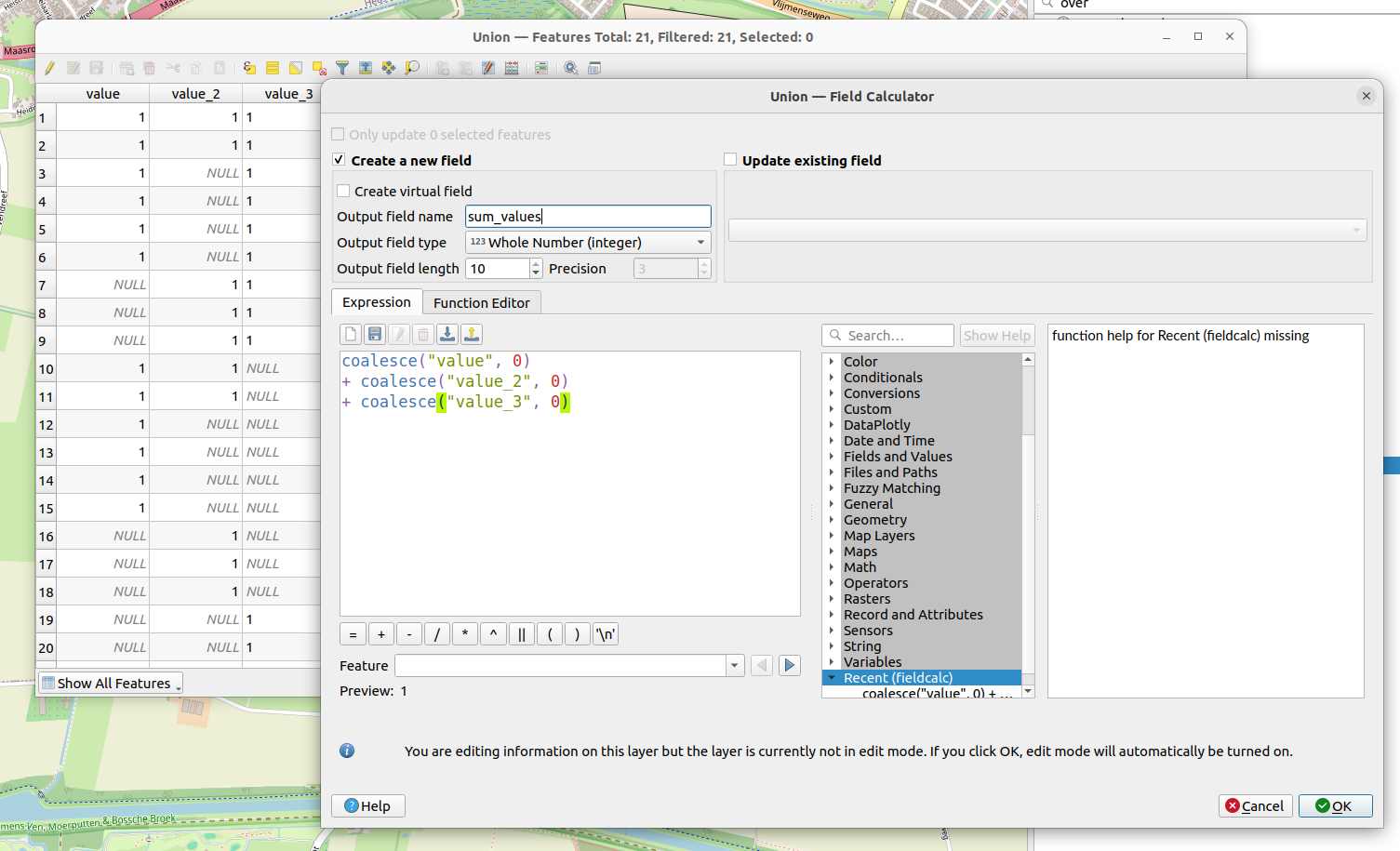
Dan processing algoritme Union (Multiple) gebruikt om een nieuwe laag te maken met alle opgeknipte stukjes polygoon. Daar zitten dan de value-kolommen in uit elke laag.
Daar kun je met de field-calculator een kolom “sum_values” bij berekenen met de expressie:
Maar ik heb bijvoorbeeld in bepaalde vlakken hogere dichtheden, en ik heb wel 2000 geomtrieen die ik een hogere value zou willen geven (omdat de dichtheid hoger is). Is er een makkelijke manier om een bepaalde groep te selecteren en deze de waarde 2 te geven? of moet ik dit allemaal handmatig aflopen?
Even als voorbeeld:
De verspreiding van de patrijs, de dichtheden verschillen van 0 - 285 patrijzen in een polygoon. Ik wil voor de groep van 1-10 patrijzen de value 1 toekennen, de volgende groep (10 - 50) value 2 en zo door en zo door.
dat wil ik makkelijk toevoegen in de attributen tabel maar kan dit ook met een expressie? want anders moet ik alles handmatig gaan doen, wat heel veel werk is. Vooral als er 1000 attributen heeft.
Moet je dan niet eerst een raster over Nederland leggen van laten we zeggen 10 × 10 km.
En dan alle gegevens eerst verdelen over dat raster en vanuit daar verder werken?
Ik roep maar iets hoor, heb er verder geen verstand van.
Toevoeging: een raster van tien bij tien op een bol oppervlak kan niet eens realiseer ik me net.
Nou ja het was maar een idee.
Dat is precies de reden om het in een database te doen. Je kunt dan queries schrijven, opslaan en en zo vaak uitvoeren als je wil zonder je steeds suf te klikken op de knoppen in QGIS. Het ligt er nogal aan hoe je dataset nu in elkaar steekt. Ik neem aan dat je niet honderden kaartlagen hebt per soort, maar weet dat natuurlijk niet zeker.
Raymond was me net voor. Het is niet echt uit je posts op te maken hoe je gegevens in elkaar steken, daarom word het lastig om je verder te helpen.
Dat gezegd hebbende:
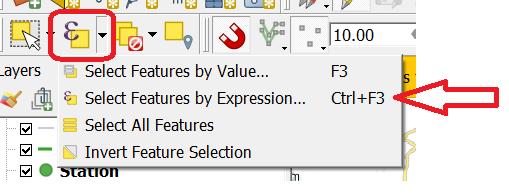
Ja, die is er. Met behulp van Select Features by Expression:
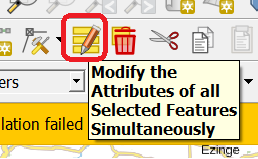
Hiermee kun je op basis van de waarde van attributen, of zelfs berekeningen, een aantal features selecteren. Als je ze geselecteerd hebt (en je laag in de Edit-modus zit!), dan kun je met de Modify-attributes-knop alle attributen voor de geselecteerde Features in 1 keer op dezelfde waarde zetten:
Tot zover het handmatige deel. Als je wat beter kunt uitleggen wat voor gegevens je allemaal hebt, dan kunnen we waarschijnlijk wel wat specifieker zijn.
Dit lijkt er op te wijzen dat je een aantal polygonen hebt, en een aantal punten. De punten bevatten een dichtheid, en die vallen binnen 1 (of meerdere?) polygonen, en op 1 of andere manier wil je dan meerdere dichtheden aan 1 en dezelfde polygoon toekennen?
Ik ben hier nu wat aan het speculeren hoor, dus kan het best mis hebben. Maar dat geeft wel aan waarom het handig is, als je meer hulp wil hebben, om wat je hebt te beschrijven. R.A. Barbers idee is zo gek nog niet, namelijk, dat is de techniek die ik toepas voor het weergeven van de begrazingsdruk van een schaapskudde op basis van hun GPS-zenders.
Ik ga een poging doen om het zo goed mogelijk uit te leggen
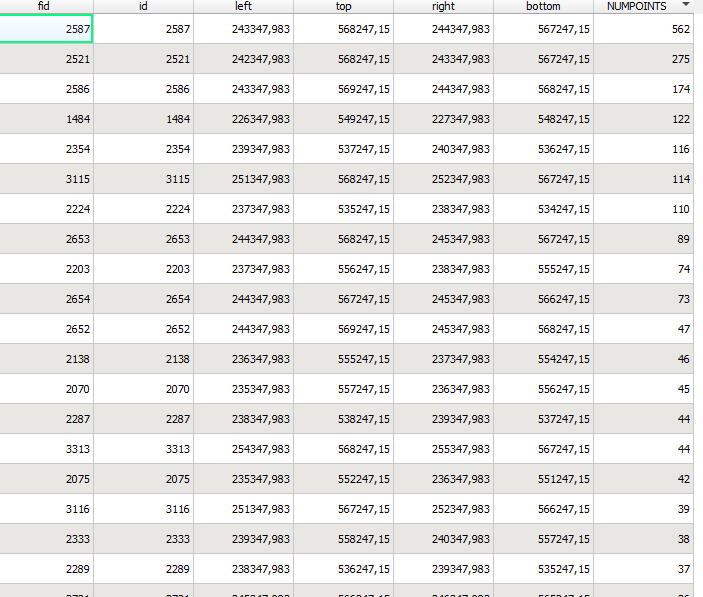
Ik heb een grid gemaakt over mijn gebied(gridcellen van een 1 vierkante km), vervolgens heb ik de ruwe data met waarnemingen van de betreffende soort. Vervolgens heb ik met de tool punten tellen in polygonen de grid cellen verschillende waardes gegeven. Hierdoor zie ik waar dus ‘hoge dichtheden’ zitten.
Dit doe ik met 3 verschillende soorten, de geelgors, veldleeuwerik en de patrijs.
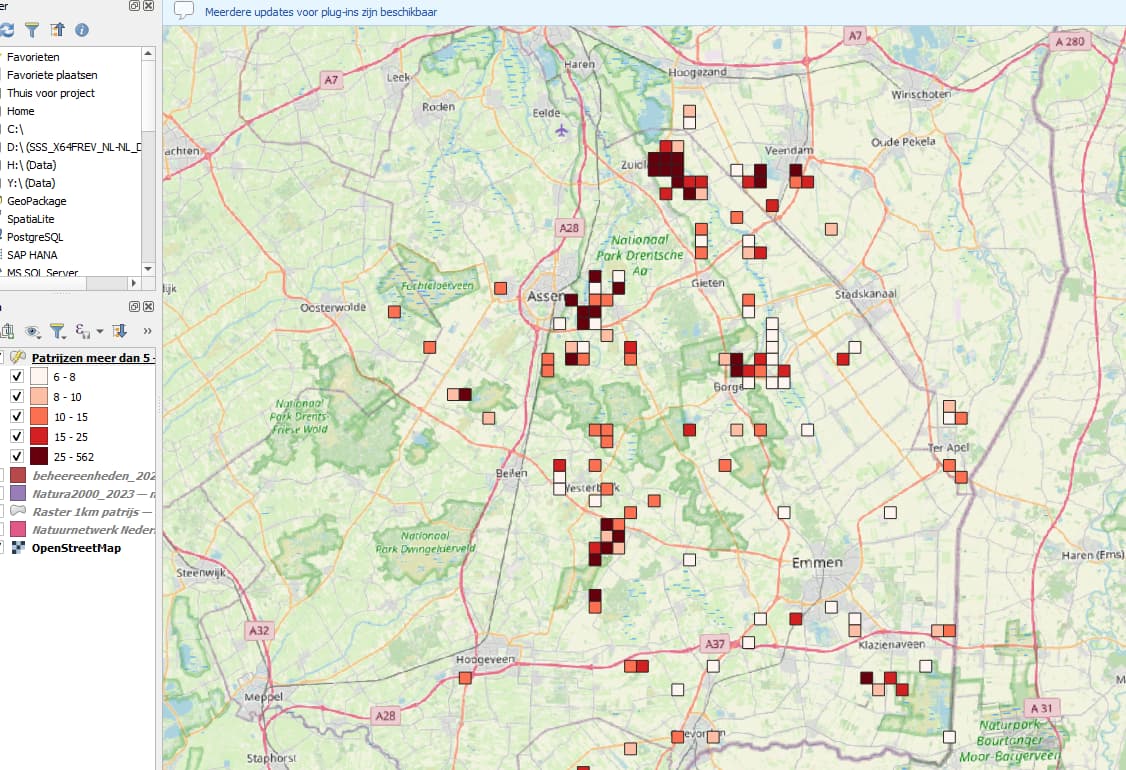
Als voorbeeld ziet dit er dus zo uit voor de patrijs:
De lijst NUMPOINTS laat dus zien hoeveel waarnemingen er in een kilometervak (grid) waargenomen.
Ik wil lage aantallen waarnemingen de value 1 geven
middel value 2
en hoog 3
Dus hiervoor moet ik een expressie gebruiken maar ik weet niet welke precies.
Alles boven de 100 waarnemingen moet value 3 krijgen. Hoe voer ik dit dan uit ?
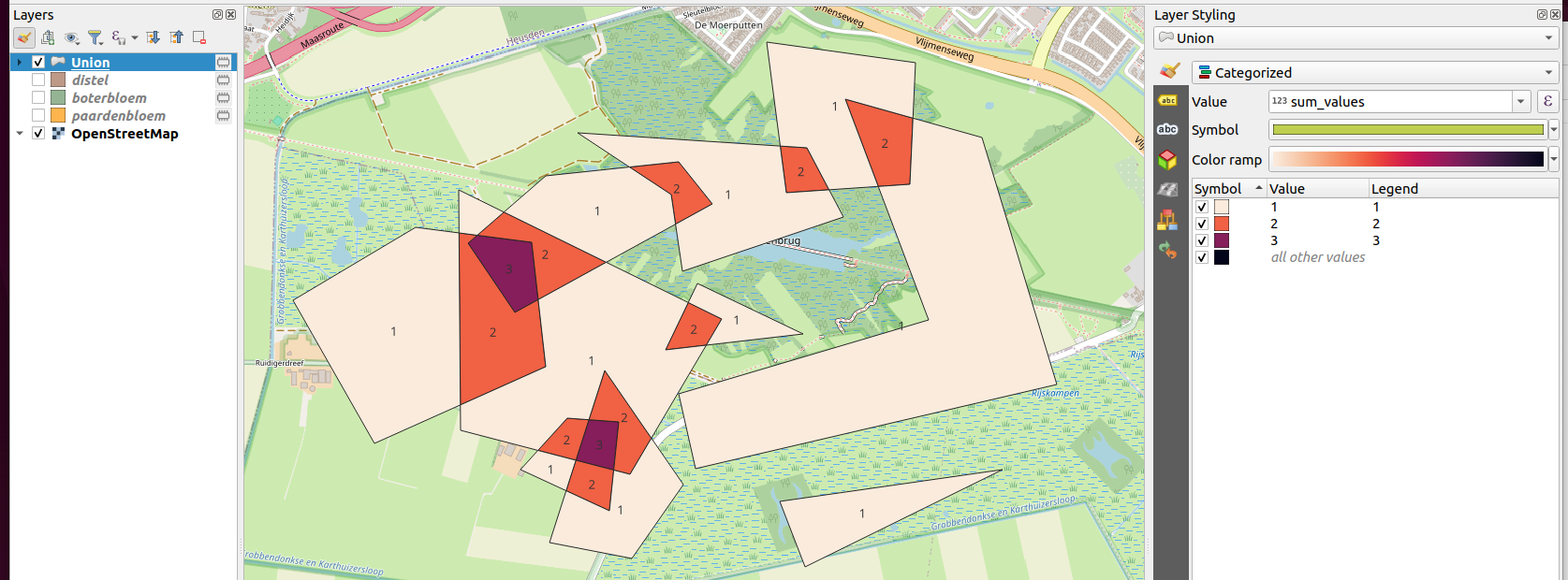
Dit zelfde principe wil ik dus ook voor de geelgors doen, en de veldleeuwerik, om vervolgens deze data allemaal over elkaar te leggen, en te weten welke hotspots er zijn. Waar beide soorten in hoge aantallen voorkomen.
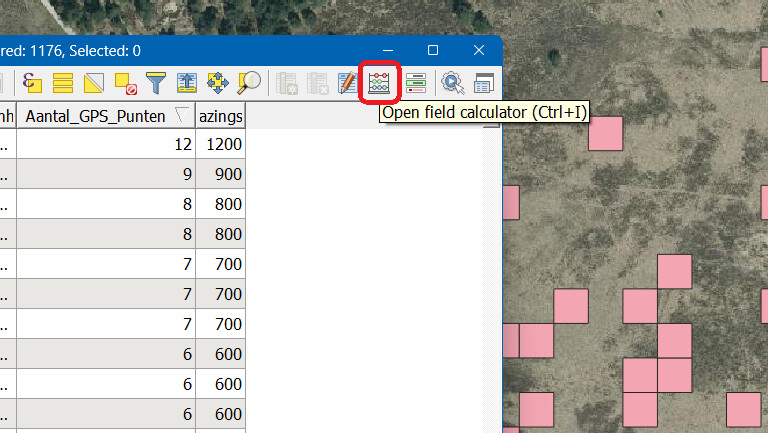
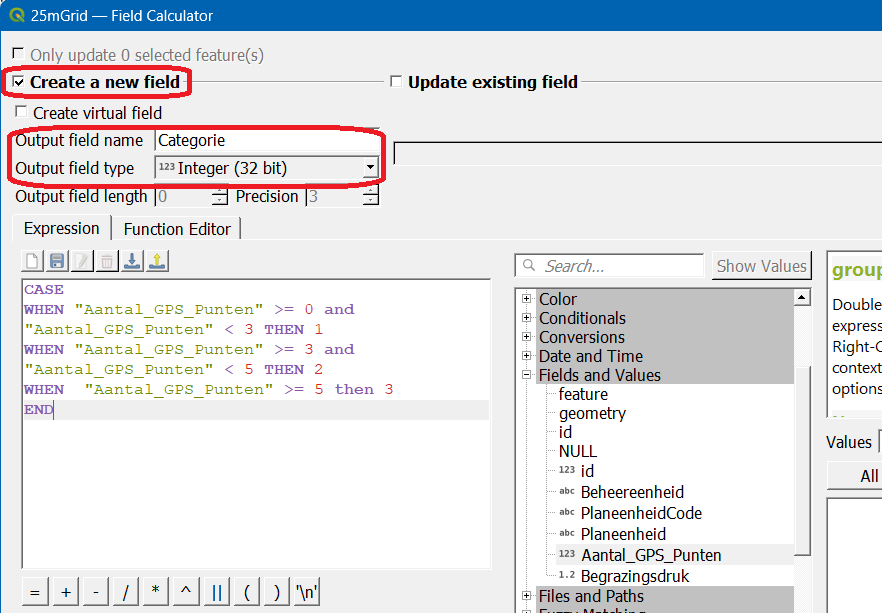
Zoals ik al zei, ik heb een vergelijkbare dataset (gridcellen zijn veeeel kleiner, en aantallen ook, maar het principe is hetzelfde). Open de Field Calculator in de tabel:
De expressie die ik gebruikt heb, is een Case-expressie:
CASE
WHEN "Aantal_GPS_Punten" >= 0 and "Aantal_GPS_Punten" < 3 THEN 1
WHEN "Aantal_GPS_Punten" >= 3 and "Aantal_GPS_Punten" < 5 THEN 2
WHEN "Aantal_GPS_Punten" >= 5 THEN 3
ELSE 0
END
Hiermee verdeel ik de waardes in categorien. Dit kun je uitbreiden of verminderen, net zoals je wil. Voor zover ik weet is er geen limiet aan het aantal When-opties dat je er in kunt zetten. Let op de ELSE aan het eind: mochten er geen waardes in het veld zitten, of anderszins iets dat niet aan de When-voorwaarden voldoet, dan word het nieuwe attribuut Categorie daar 0. Zo kun je fouten afvangen.
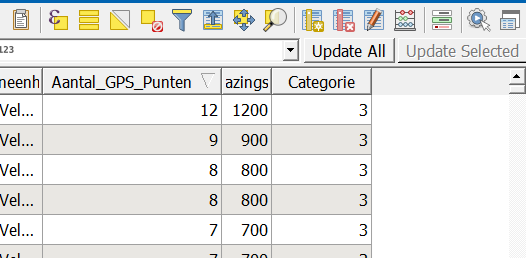
Als je nu op OK klikt, dan zie je dat er een nieuw attribuut Categorie is toegevoegd:
Succes! als je nog verdere vragen hebt, laat het gerust weten. Oh, en misschien is deze handig voor je: https://www.qgistutorials.com/nl/
Harstikke bedankt, dit werkt echt perfect !!! Mijn dank is groot !!
Als ik dit nu helemaal verwerk krijg ik dus een bepaalde uitkomst.
Bijvoorbeeld ik krijg dus op een grid de waarde 6 (2 van geelgors en 4 van patrijs). Hoe kan ik dat makkelijk terug zien? Want ik moet natuurlijk wel snel kunnen zien welke van de soorten de "meeste bijdrage levert’
Want uiteindelijk moet ik dit met 5 soorten combineren, en vanuit daar wel kunnen zien of 1 van de soorten een ‘grote bijdrage’ levert
Persoonlijk zou ik dat doen door voor elke soort een categorie-kolom op te nemen in het eindresultaat, denk ik. Die kun je daarna in (alweer ) een nieuwe kolom bij elkaar optellen. Ook zou je dan in een kolom GrootsteBijdrage de naam van de hoogste bijdrager kunnen opnemen bijvoorbeeld.
Met behulp van de case en if statements in de Field Calculator moet dat wel lukken, denk ik. Op Stackexchange vond ik een mooi voorbeeldje van een vergelijkbare vraag, dat bied je alvast een uitgangspunt.
Overigens is dit een manier, misschien zijn er nog anderen die meelezen die een goed idee hebben. Maar ik denk dat ik zoiets zou doen. Is natuurlijk wel een beetje afhankelijk van hoeveel soorten je hebt, als dat er veel zijn dan word dit wat omslachtig.

 ) een nieuwe kolom bij elkaar optellen. Ook zou je dan in een kolom GrootsteBijdrage de naam van de hoogste bijdrager kunnen opnemen bijvoorbeeld.
) een nieuwe kolom bij elkaar optellen. Ook zou je dan in een kolom GrootsteBijdrage de naam van de hoogste bijdrager kunnen opnemen bijvoorbeeld.