Bij sommige selecties/views gebruik ik de kolom begingeldigheid, maar zonder (eerder) rekening te houden met null waarden. Ik denk dat die onwenselijk zijn, want ze maken queries nodeloos ingewikkeld en een default lage waarde is dan te prefereren wat mij betreft.
Vanwege de vele afhankelijkheden kon ik de view queries moeiijk direct aanpassen en heb dus de brontabellen geupdate:
update verblijfsobject set begingeldigheid=‘1900-01-01’ where begingeldigheid is null;
UPDATE 410
test=# update pand set begingeldigheid=‘1900-01-01’ where begingeldigheid is null;
UPDATE 382
test=# update nummeraanduiding set begingeldigheid=‘1900-01-01’ where begingeldigheid is null;
UPDATE 5
test=# update openbareruimte set begingeldigheid=‘1900-01-01’ where begingeldigheid is null;
UPDATE 2
test=# update woonplaats set begingeldigheid=‘1900-01-01’ where begingeldigheid is null;
UPDATE 0
(hetzelfde geldt voor ligplaats en standplaats),
waaruit de aantallen blijken, want de ingevulde waarde mag wat mij betreft ook wat anders zijn, zolang de datum maar in het verleden ligt.
Er is tenminste 1 geval van een nu vigerend verblijfsobject waar begingeldigheid null is, met identificatie 0755010000002165.
Mijn bron is de atom feed van december.
Na de januari update kan ik desgewenst alle gevallen leveren, maar de primaire vraag is of deze null waarden geacht worden verbetering te behoeven.
Mijn vraag is of deze gevallen gemeld moeten worden.
Alvast dank,
Jan
ik heb slechte ervaringen met een vigerende lage default waarde. Zeker als deze waarde ook een werkelijke waarde kan zijn (denk aan bouwjaar 1900).
Nu bedenk ik me dat 29 februari van een niet-schrikkeljaar misschien een mooie work-around kan zijn. Enerzijds is altijd terug te zien dat het geen werkelijke waarde kan zijn, en anderzijds is het wel een waarde om mee te werken.
Wat is de LV-publicatiedatum van die null-waarden? Liggen die allemaal zo rond 2010, ten tijde van de opbouwfase van de BAG?
Goed idee, in principe. Alleen wil postgres checkt postgres bij initialisatie van een date type, dus:
select date(‘1801-02-29’);
ERROR: date/time field value out of range: “1801-02-29”
(met 28 ipv 29 gaat het goed). Aannemend dat postgresql toch een vitale schakel is, lijkt dat een probleem.
Je vraag over de LV-publicatiedatum moet ik even in reserve houden tot de januari atom-feed beschikbaar is. Ik heb nu de null waarden al overschreven, zoals boven aangegeven en een check op het aantal verblijfsobjecten met begingeldigheid 1900-01-01 is 2882, dus ik kan ze even niet achterhalen.
Mogelijk is er toch al eerder een default ingesteld op 1001-01-01, dat komt iig uit select min(begingeldigheid) from verblijfsobject; Ook andere tabellen geven dit resultaat.
Meer informatie over de begingeldigheid is terug te vinden in de BAG catalogus. 9 Implementatie
Het is binnen de voorschriften toegestaan elke geldige datum in het verleden of de toekomst te gebruiken binnen het formaat (jjjj-mm-dd). Voor het verblijfsobject met ID 0755010000002165 is datum 1000-01-01 geregistreerd als begingeldigheid (en brondocumentdatum). Alles wijst erop dat dit een invoerfout is. De datum voldoet echter aan het vereiste formaat en is daarom ‘gewoon’ vastgelegd in de BAG.
Ik ben overigens benieuwd waar je de begingeldigheid voor gebruikt. Als je bijvoorbeeld wilt bepalen welk voorkomen nu geldig is hoef je alleen maar voorkomens met een begingeldigheid in de toekomst te negeren.
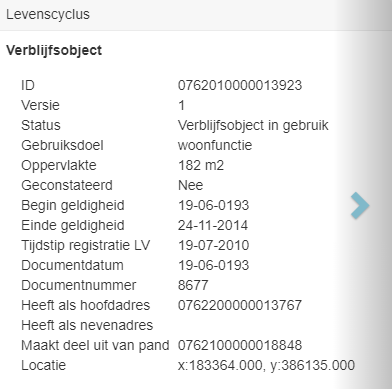
Uit nieuwsgierigheid heb ik zelf ook nog even in de database van de BAG gekeken. De oudste Begingeldigheid bij een verblijfsobject is 0139-06-01. Zie het verblijfsobject met ID: 0762010000013923
Dit verblijfsobject is echter al gemuteerd waardoor het actuele voorkomen een gangbare Begingeldigheid heeft.
Er zijn overigens op dit moment nog 599 actuele voorkomens van adresseerbare objecten met een Begingeldigheid die eerder in de tijd ligt dan 1 januari 1900. 41 van deze voorkomens hebben 1 januari 1000 als begindatum.
Daar ben ik het niet mee eens. Nodeloos ingewikkeld? Welnee, zo ingewikkeld is een null-check niet. En uit de deze discussie zie je al hoe veel foutgevoeliger een magic datum is. Want er zijn zat bouwwerken die ouder zijn dan 100, 200 of zelfs 500 jaar. Dus waar leg je de grens? Mijn eigen huis is al ouder dan 100 jaar…
Bovendien is het vanuit datamodel-technisch opzicht een verkeerde keuze. Want als iets onbekend is, dan moet het ook echt onbekend, en dus null zijn. En niet een willekeurige waarde bevatten…
Het wordt ingewikkeld omdat je in voorkomende gevallen van (on)gelijkheid gebruik maakt, echter in (postgre)sql is levert de vergelijking tussen een waarde en null uitkomst null en niet true/false, zodat “and a<>b” door null waarden uit kan lopen op “and (a<>b or a is null or b is null)”. Zelfs als het overkomenlijk is, is het hinderlijk en een bron van fouten als je er niet steeds op let.
En begingeldigheid leek mij een goede kandidaat voor “not null” constraint.
Dank, alweer!
Ik gebruik begingeldigheid voor reconstructie van historische basisdata voor de populatie service, waarbij, gezien het feit dat er ook begingeldigheid in de toekomst voorkomt, ook de actuele set in die zin historisch is.
Hier een samenvatting van de bestaande gevallen in de inspire dataset:
select substr(identificatie,1,4) gemeenteid, tijdstipregistratie::date "datum registratie", count(*) from verblijfsobject where status='Verblijfsobject in gebruik' and begingeldigheid is null and eindgeldigheid is null group by gemeenteid,"datum registratie";
gemeenteid | datum registratie | count
------------+-------------------+-------
0310 | 2010-12-29 | 4
0755 | 2010-12-06 | 37
Elke grote relationele database doet dat zo (ik meen dat het zelfs ANSI-sql is), en dat is ook zoals het hoort. null is immers onbekend, niet gedefinieerd. Dus alles wat je daarmee vergelijkt is automatisch niet waar, omdat je het niet weet.
In dergelijke gevallen is het ook beter, en leesbaarder, om de vergelijking om te draaien en te vergelijken op “is gelijk aan”. Want in dat geval levert een null-waarde aan welke kant van de vergelijking dan ook het juiste resultaat op: is niet gelijk.
Dat is dus puur een kwestie van hoe je je vraag formuleert (en geloof me, er zijn altijd manieren om dat om te draaien). Bovendien is het database-technisch beter, want met een = vraag kan de database veel beter gebruik maken van de indexes. Bij een <> loop je al heel snel het risico van een full table scan, en bij aantallen rijen zoals de BAG wil je een FTS daar vermijden (een FTS is niet noodzakelijkerwijs slecht, maar het kan wel een drempel zijn voor je performance).
Mocht je toch de voorkeur geven aan een is niet gelijk aan selectie, dan is MINUS (of in PostGreSQL EXCEPT ook een goede optie, daar houd je het ook leesbaarder mee.
Dank. Ik zal nagaan waar ik een verbetering kan aanbrengen, want ik heb idd niet erg m’n best gedaan om een omkering te vinden. In het geval van < of > (datum vergelijk) moet ik er ook nog even over nadenken. Ws vervang ik deze null waarden weer in mijn lokale tabellen, en ik zag onder het typen advies over het gebruik van de coalesce() functie langs komen.
Het is dus doenbaar met null-waarden, maar, om een oude zegswijze te hergebruiken:
Verder vind ik nog steeds dat, vanuit de systematiek van de BAG, verwacht mag worden dat gegevens over geldigheid altijd ingevuld worden en dus een not null constraint verwacht mag worden in dit en dergelijke gevallen.
Tenslotte: voor pand krijg ik de volgende gegevens over registratiedata en gemeenten:
select substr(identificatie,1,4) gemeenteid, tijdstipregistratie::date "datum registratie", count(*) from pand where status like 'Pand in gebruik%' and begingeldigheid is null and eindgeldigheid is null group by gemeenteid,"datum registratie";
gemeenteid | datum registratie | count
------------+-------------------+-------
0302 | 2010-12-21 | 2
0345 | 2010-12-07 | 1
0399 | 2009-10-07 | 1
0755 | 2010-12-06 | 120
0809 | 2010-12-28 | 1
Voor de overige tabellen zijn de aantallen te klein om me druk over te maken.
Vooral bij de gemeente Boekel is dus winst te halen.
Ik probeer af te ronden vanuit mijn gezichtspunt, met dank aan een ieder en een laatste verzoek.
dataset in kwestie: De niet inspire geharmoniseerde NL adressen via Introductie - PDOK. Daar was ik niet duidelijk over, in de war omdat in de BAG v1 tijd de dataset als inspireadressen.zip benoemd was, nu lvbag-extract-nl.zip.
Dit is de dataset waar het mij steeds om gaat.
Dan de opmerking/het verzoek: Ik merkte vandaag dat in de gedownloade dataset null waarden in postcodes zijn vervangen door ‘0’.
Daarom het parallelle verzoek om null waarden in begingeldigheid in de extract op een zelfde manier te behandelen (‘0001-01-01’ voldoet, terwijl we boven gezien hebben dat ‘1001-01-01’ mogelijk deze functie heeft vervuld in enkele gevallen).
Ik zie niet direct nog andere kolommen om dit te willen, ook omdat bijv. tijdstipregistratie en voorkomenidentificatie ws automatisch via bijv. een trigger functie ingevoerd worden.
Voor mij had overigens de algehele vervanging van null postcode door ‘0’ niet gehoeven. null heeft hier een denkbare betekenis/functie, onderscheiden van ‘0’, waarbij null betekent: niet ingevoerd en ‘0’ effectief kan betekenen: (heeft) geen postcode.
Bij mij veroorzaakte dat een “view hell”, dwz de noodzaak om (al dan niet materialized) views met dependencies hierop in te richten, zodat overige queries onveranderd kunnen blijven.
Met weglating van tussenregels, ter toelichting, de situatie wb postcodes in de tabel nummeraanduiding:
select count(*) from nummeraanduiding where postcode is null;
0
select count(*) from nummeraanduiding where postcode='';
0
select count(*) from nummeraanduiding where postcode='0';
1032385
Voorheen waren dit null waarden. De meeste betreffen ‘overige gebruiksfuncties’ zonder postcode, dus het hoge aantal is geen reden tot paniek :).
Ik moet iets bekennen. Bovenstaande klopt niet (‘0’ ipv null). Sorry, toen ik ook ‘0’ tegenkwam bij huisletter etc., ben ik diep gaan graven en heb gemerkt dat er een fout zat in een programmaregel, waar () nodig waren, maar ontbraken. Eerder geen last mee gehad op de een of andere manier. Lijkt of de compiler strikter geworden is, iets anders heb ik nog niet kunnen bedenken.
Excuus.