Per vandaag zijn bij PDOK de geactualiseerde datasets CBS Postcode4 en Postcode6 beschikbaar. De services van postcode4 en postcode6 bieden per afzonderlijk vlak statistische gegevens over demografie, woningen, energie, inkomen, sociale zekerheid, nabijheid van voorzieningen en dichtheid. Bij deze update zijn de gegevens over de jaren 2021 en 2022 aangevuld. Het peiljaar 2023 is toegevoegd.
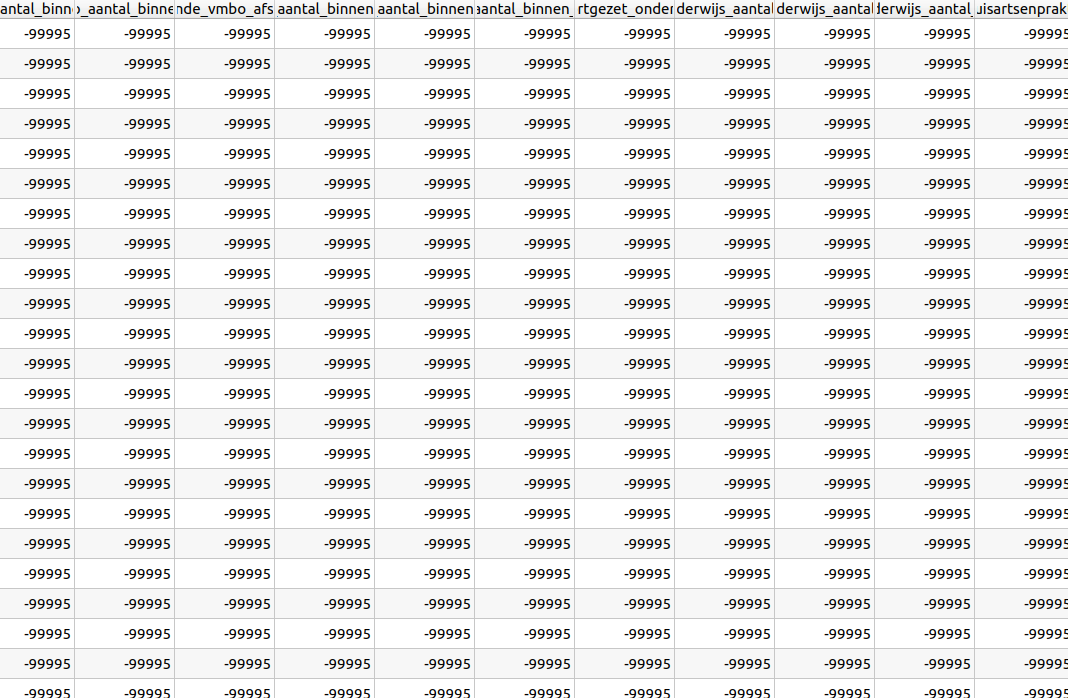
De postcode 4 gpkg heeft heel veel kolommen met alleen maar waarden -99995 etc. Ik denk nodata/NULL waarden maar dan in een jaren '80 notatie. Is dat de bedoeling?
Ik vermoed wel dat dat helaas de bedoeling is Raymond, want het CBS zelf levert deze data zowel als Shapefile als GeoPackage. Ik zou het CBS adviseren om dat voor de GeoPackage export even aan te passen
Het klopt inderdaad dat de waarde -99995 en -99997 is aangeleverd. Dit is zo afgesproken tussen CBS en PDOK. Sommige data is namelijk nog niet beschikbaar en wordt later aangevuld.
Deze week was ik samen met Jeroen Hovens de Postcode6 gebieden aan het analyseren, en daarbij kwamen we tot een vreemd inzicht: er liggen blijkbaar postcodegebieden geometrisch volledig los van de omliggende postcodegebieden!
Na inladen van de hele dataset in PostGIS kun je dat met een simpele query uittesten:
SELECT p1.*
FROM cbs.postcode6_2023 AS p1
LEFT JOIN cbs.postcode6_2023 AS p2
ON ST_Intersects(p1.geom, p2.geom) AND p1.fid != p2.fid
WHERE p2.fid IS NULL;
Hier komen dan 274 postcodes uit rollen.
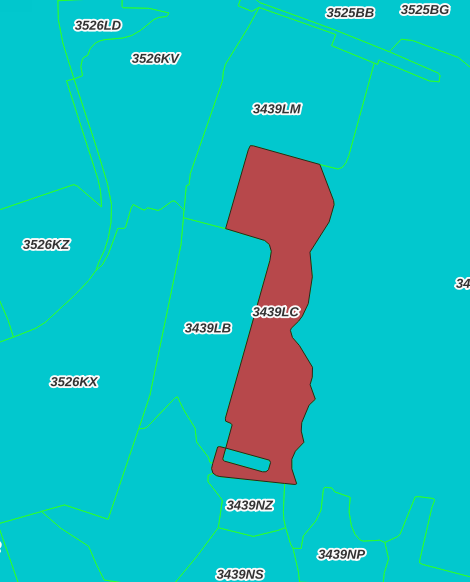
Nadere bestudering in de kaart laat zien dat dit allemaal multivlakken zijn waar ogenschijnlijk een zelfkruising in zit. Neem bijvoorbeeld postcode 3439LC: linksonder zit zo’n zelfkruising.
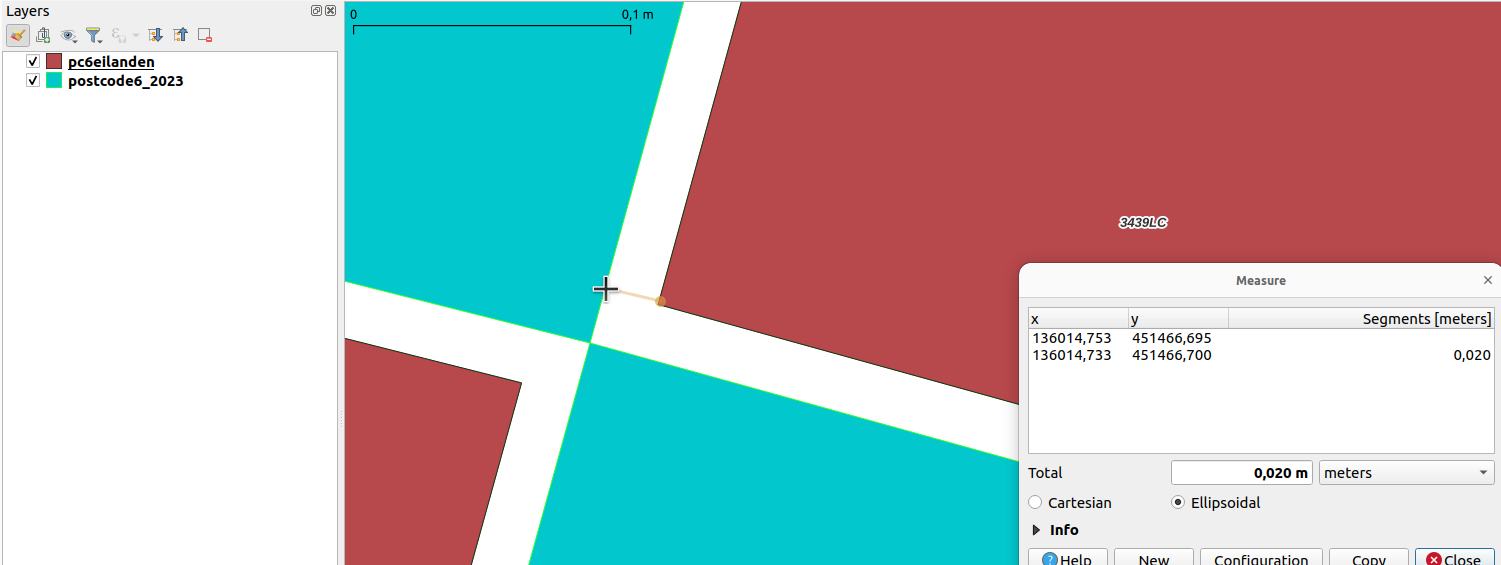
Het lijkt erop dat bij dit soort vlakken een correctie (op de zelfkruising?) is toegepast door te bufferen met een (negatieve) buffer van -0,02 meter.
Heeft iemand een idee hoe dit in z’n werk gegaan is? Uit de documentatie op PDOK meen ik op te maken dat de vlakken uit de ESRI postcode kaart komen. Maar dit is dus niet helemaal oké, even los van eventuele andere (inhoudelijke) tekortkomingen.
Deze kaart bevat een licht versimpelde geometrie van de postcodekaart van ESRI. Het origineel is bijna 1 Gb, deze versie is licht gegeneraliseerd naar 250 Mb. De kaart met gegevens wordt gepubliceerd via PDOK. Dit levert problemen op bij Geoserver met multivlakken die elkaar met 1 punt raken. Vandaar een binnenwaartse buffer van 2 cm. Wij kunnen er mee leven.
dank voor de toelichting. Deze situatie tref je ook aan in de CBS download van de postcode 6 geopackage via Kerncijfers per postcode | CBS
Ik ben persoonlijk al heel blij dat er eindelijk een postcodevlakken kaart gedeeld wordt via CBS (zijnde een publieke instantie) en dan ook nog makkelijk toegankelijk als .gpkg.
Veel partijen maken wel gebruik van postcodes om data te structureren en te delen. Netbeheer Nederland doet dit bijvoorbeeld op het zeer actuele thema van netcongestie door de capaciteitsinformatie per pc6 als csv aan te bieden, zonder de geometrie mee te leveren of te verwijzen naar een compatibel pc6 geometrie-bestand.
Met de geometrie van CBS (en indirect ESRI) is die data eenvoudig te visualiseren en ruimtelijk te analyseren in eigen GIS omgevingen.
Dat de pc6-vlakken topologisch niet aansluiten en soms overlappen is wel jammer, dat maakt ruimtelijke analyses moeilijk. De originele dataset van ESRI bevat ook overlap, gaten en ongeldige geometrieën voor zover ik kon zien.
Neem bijvoorbeeld een 1e graads buren analyse zoals bijvoorbeeld een postcode-roos. Touches of Intersects werkt dan niet goed. Wellicht een st_dwithin met bijvoorbeeld 10 cm zou dan een goed resultaat geven?
Postcodes zijn simpelweg geen gebieden, ze worden uitgegeven aan adressen. Die hebben een punt (verblijfsobject) in de BAG en met die punten kun je gaan knutselen en vlakken genereren. Daarbij moet je allerlei aannames doen.
Zo gebruikte ik ooit de woonplaatsgrenzen uit de BAG, omdat postcodes in principe altijd in dezelfde woonplaats liggen. Maar de woonplaatsgrenzen sluiten ook niet goed aan, en daardoor mijn postcode-gebieden ook niet. Ik vermoed dat je altijd problemen houdt.
Je kunt het ook zelf proberen met de BAG, dan zul je wel merken dat het niet zo makkelijk is.
@NiekvanLeeuwen, als je een buffer met afstand 0 doet (met JTS of GEOS) worden die polygonen ook gefixt voor GeoServer.
Op de PostGIS dag in 2019 was er een presentatie van Arend jan van der Neut: hij liet de resultaten zien van het genereren van postcode6-gebieden door middel van een PostGIS query. Zag er in elk geval toen in de presentatie erg goed uit. Ik geloof echter niet dat het gebruikte script openbaar toegankelijk is, maar wellicht loont het om hem te benaderen als je meer wil weten.
Er zitten de nodige ontwerpkeuzes in ons model om te komen tot postcodevlakken. Wat terecht wordt aangegeven is dat er geen postcodevlakken bestaan, dus het is een gemodelleerd bestand (waar in diverse situaties handig kan zijn). De BAG-adressen die als basis dienen kennen een aantal bijzondere situaties, bijv. flats met punten op elkaar met verschillende postcodes. Of een BAG-beheerder in een andere gemeenten die de punten in een flat wel naast elkaar tekent, maar nog steeds verschillende postcodes om en om wisselen. Toen we ons hier jaren geleden in zijn gaan verdiepen hebben we hilarische situaties ontdekt. Ook wel eens teruggemeld, zoals toen we een ‘smiley’ ontdekten van ingetekende adrespunten.
We maken de postcodevlakken en delen deze als open data. Dit stelt o.a. CBS in staat om die gegevens op te pakken en te combineren met de statistische gegevens en dat als nieuwe combinatie ook weer verder te delen. Over enkele weken gaan we weer starten met de actualisatie voor 2025. CBS/PDOK ontsluit een gegeneraliseerde versie. Het kan onverhoopt voorkomen dat ook in onze bron wat eigenaardigheden voorkomen (oke, die zijn er sowieso gegeven wat ik hierboven heb beschreven).
Wat overpeinzingen: @NiekvanLeeuwen zou het mogelijk zijn om voor de atomfeed/download juist de niet-(negatief)gebufferde versie beschikbaar te stellen?
@JBak ik vind de generalisatie van het CBS (Douglas-Peucker met 1 meter, schat ik) nog wel een mooie toevoeging aan de Esri versie. Scheelt een factor 5 in de omvang van de file geodatabase.
Hebben jullie dit zelf ook al overwogen?
Uiteindelijk is de positie van de adrespunten arbitrair; de BAG stelt althans geen eisen aan de positionele nauwkeurigheid daarvan
@Allen: weergaveprobleem in Geoserver? Als het om PDOK gaat is het toch Mapserver?
We maken bij PDOK inderdaad gebruik van Mapserver. Of het Geoserver of Mapserver als implementatie is, de backendimplementatie zou niet uit moeten maken, wat wel relevant is dat we bij PDOK valide geometrieën nodig hebben voor correcte werking van de services Zie ook deze omschrijving van PostGIS. Bij invalide geometriën zou PDOK een interpretatie moeten doen, waarbij PDOK dat alleen kan doen op een manier die generiek / datasetonafhankelijk is. Het is dan beter als de dataset eigenaar hier keuzes in maakt zoals @NiekvanLeeuwen hierboven beschrijft en onderbouwt. Alleen simplify kan inderdaad invalide geometrieën opleveren.
Een aantal antwoorden.
Publicatie gebufferde en niet gebufferde versie. Ik denk dat PDOK daar niet gecharmeerd van is. Mogelijk met een kleinere buffer (=0) proberen.
Het is inderdaad Mapserver welke PDOK gebruikt.
De lichte generalisatie is zoals Jan-Willem noemt. Deze past vooral de mooie cirkelbogen iets aan.
Postcodes komen wel degelijk in meer dan een gemeente voor, dat zijn enkele tientallen postcodes. Vanuit het proces van PostNL is dat ook wel te begrijpen. Ook komen er postcodes in twee BAG-woonplaatsen voor. Dat zijn er iets meer.