Ik probeer een overzicht te maken van alle wijken en in welke woonplaats(en) deze wijk ligt. Ik heb al vele datasets afgespeurd en ook dit forum, maar heb nog geen succes. Ik ben nieuw in de wereld van geodata dus hopelijk kunnen jullie me in de juiste richting wijzen. Wat ik reeds heb gedaan:
Dataset CBS Wijk- en buurtkaart 2023 gebruikt om de geografische data van wijken en buurten op te halen en dit in postgis gezet (dit had achteraf gezien ook gekund met de dataset CBS Gebiedsindelingen vermoed ik). Ik heb dit gedaan door de geopackage file te converteren naar GeoJSON.
Individueel de coordinaten van plaatsen opgehaald via de NGR BAG WFS. Hier krijg ik namelijk in JSON een MultiPolygon terug. Die stop ik ook in m’n postgis database. Nu is het geloof ik niet de bedoeling dat ik deze service hiervoor gebruik, want dat betekent 2501 requests (er zijn 2501 woonplaatsen). Ik heb dit nu handmatig gedaan voor een paar plaatsen, maar wil uiteindelijk dit voor alle plaatsen doen. Daarom heb ik gekeken naar de dataset BAG Extract 2.0, maar daar zie ik geodata in de vorm van <gml:LinearRing> en ik weet niet of/hoe ik dit moet gebruiken.
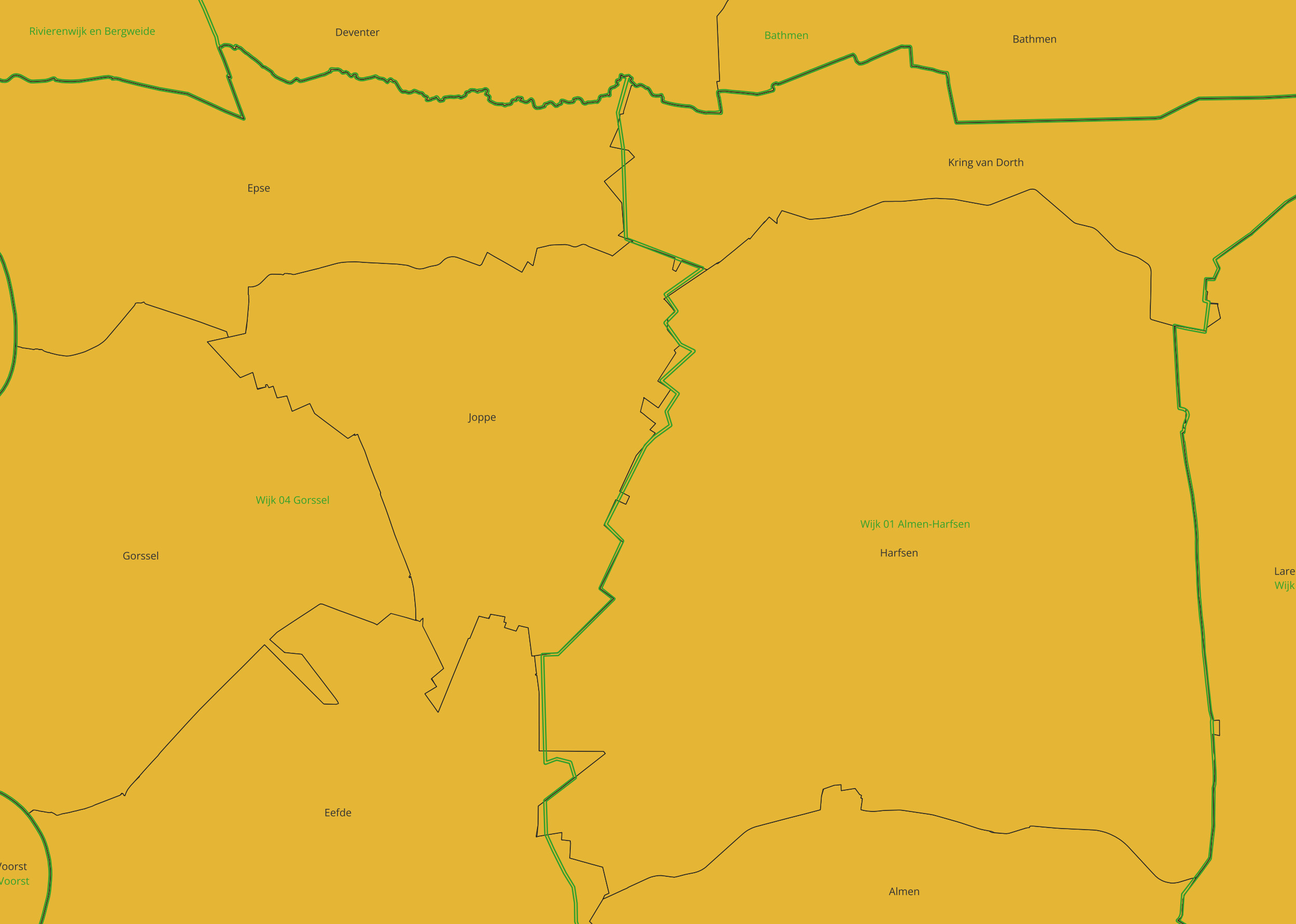
Vervolgens heb ik een ST_Intersects() query uitgevoerd om te kijken in welke woonplaats(en) een wijk ligt. Nu krijg ik daar niet het verwachtte resultaat, er komen namelijk teveel woonplaatsen terug en ik vermoed dat dat komt doordat sommige punten elkaar net raken. Als voorbeeld heb ik Wijk 04 Gorssel gebruikt, omdat deze wijk in het buitengebied ligt en 4 woonplaatsen bevat (Gorssel, Eefde, Epse, Joppe). Ik krijg echter ook de omliggende plaatsen terug (bijvoorbeeld Deventer en Harfsen).
Ik hoor graag wat ik fout doe. Als er andere manieren zijn om tot de dataset te komen die ik wil dan houd ik mij ook aanbevolen.
De dataset gebiedsindelingen van het CBS bevat gegeneraliseerde grenzen, dus daar moet je wel rekening mee houden.
Je kunt ook de BAG Geopackage downloaden (is wel 7Gb!), en daar de laag woonplaatsen uit halen. Maar 1 request voor alle 2501 woonplaatsen naar WFS zou geen probleem mogen zijn hoor. De grens zit op 10.000, dus daar blijf je met de woonplaatsen ruim onder.
Hier loop je tegen het probleem aan dat woonplaatsen (en Wijken volgens mij ook) landsdekkend zijn. De grens van een woonplaats is ook de grens van de naastliggende woonplaats, die liggen dus op elkaar. Een ST_Intersects zal daardoor ook de aangrenzende vlakken teruggeven. Zelf zou ik dat voorkomen door de wijken negatief te bufferen, met een afstandje van 1 tot 5 meter of zo. Dan word het vlak wat kleiner, en trekt zich als het ware terug van het naastliggende vlak, zodat de grenzen niet meer overeen komen.
Oh, en gebruik je alleen PostGis? Zelf zou ik daar ook QGis bij gebruiken, omdat je dan ook visueel de zaak kunt bekijken. Maar misschien gebruik je al wat anders om je data te visualiseren, dat weet ik niet. Dit soort operaties kun je namelijk ook prima in QGis doen.
En mocht je nog meer vragen hebben, altijd welkom om ze hier te stellen
Kleine toevoeging, je hoeft niet de hele GPKG te downloaden als je de mogelijkheid hebt om bijvoorbeeld ogr2ogr te gebruiken met Virtual File Systems. Dan is het mogelijk direct alleen de woonplaatsen te downloaden met een oneliner. En dan hoeft je alleen op de +/-30Mb te wachten i.p.v. 7Gb.
Na wat spelen in QGis lijkt het er op dat mijn aanpak niet helemaal gaat werken. De grenzen lijken elkaar niet altijd te volgen. Zo zou Wijk 04 Gorssel nog steeds ook in Harfsen liggen, zie screenshot hieronder.
Hebben jullie een idee waardoor er verschil in de grenzen zit? Of suggesties om op een andere manier tot de gewenste data te komen?
De Wijken en Buurten worden bijgehouden door het CBS, de Woonplaatsen zijn de gemeentes verantwoordelijk voor. Het lijkt er op dat die twee hun grenzen in nog mindere mate dan ik dacht op elkaar afstemmen. Ik heb er eens wat beter naar gekeken n.a.v. jouw screenshot, en die grenzen liggen enorm uit elkaar. Technisch gezien klopt het dus wel dat Wijk 04 Gorssel in Harfsen ligt, want beide vlakken overlappen elkaar, maar het is niet wat je verwacht. Ik had zelf ook niet verwacht dat die twee grenzen zo veel van elkaar zouden verschillen, eerlijk gezegd. Hier en daar een flintertje of zo: ja, maar niet dit…
Je zou een aantal dingen kunnen proberen:
Bereken het percentage overlap voor elke wijk/woonplaats, en leg dan ergens proefondervindelijk een ondergrens: voor een echte overlap moet het percentage meer dan zoveel % zijn (daar zul je wat mee moeten spelen voor een goede waarde).
Maak de negatieve buffer 300 meter of zo - alleen ga je dan risico’s lopen in stedelijk gebied, waar de wijken kleiner zijn dan de woonplaatsen ipv andersom.
Neem de centroide van elke woonplaats, en kijk in welke wijk de centroide ligt. Gebruik dan wel ST_PointOnSurface in plaats van ST_Centroid, omdat ST_Centroid niet garandeert dat de teruggegeven centroide ook daadwerkelijk in het vlak ligt - STPointOnSUrface garandeert dat wel.
Elke methode heeft z’n voor- en nadelen. En van alledrie verwacht ik niet dat je een 100% resultaat kunt behalen, er zal altijd een marge overblijven dat fout gaat vermoed ik.
ik zou voor elke wijk het % overlap met alle woonplaatsen die die raakt berekenen. en dan aannemen dat de wijk ligt in de woonplaats met de grootste overlap.
Bedankt voor de suggesties. Ik heb nu eerst geprobeerd de overlap te berekenen, maar krijg altijd 100%. Dat lijkt te komen doordat de Overlap analysis tool de gehele layer gebruikt in plaats van de losse polygons, aldus deze Reddit comment. De suggestie die daar gedaan wordt begrijp ik echter niet helemaal:
“Calculate an attribute with the areas of the District and Region polygons first, then use Union on them to make a new layer.”.
Ik weet niet helemaal hoe ik dit doe. De union tool geeft geen resultaat. Hopelijk kunnen jullie me iets verder de weg wijzen.
Het is inmiddels gelukt! Met een beetje begrijpend lezen en ChatGPT kom je een heel eind
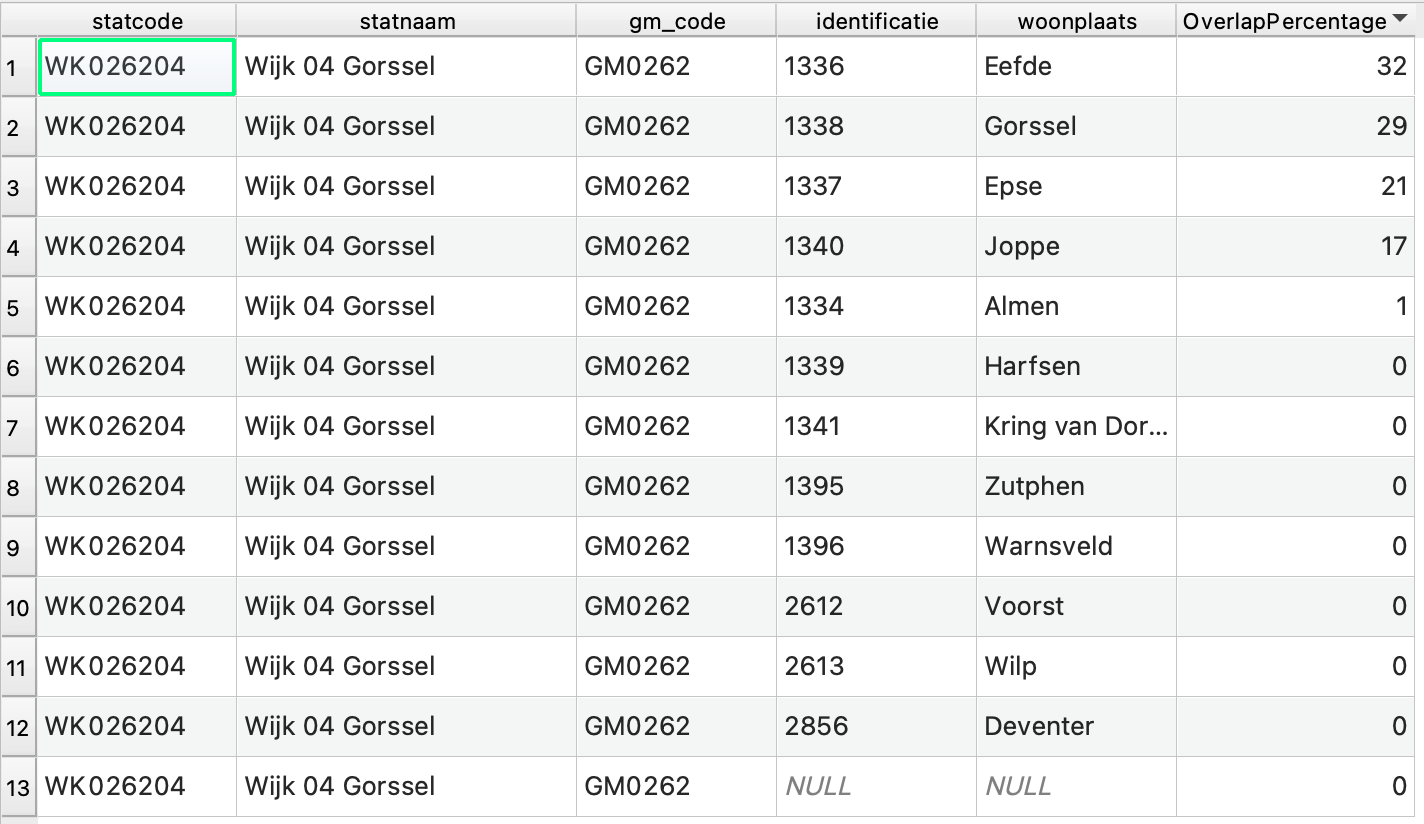
Ik heb uiteindelijk met de $area function en de Union tool het percentage overlap weten te berekenen en hier kan ik mee verder.
Nogmaals veel dank voor alle hulp!
Om bij het originele voorbeeld te blijven, hier het resultaat:
En tsja, Wijk Gorssel ligt vooral in Eefde, niet eens in Gorssel

 .
.