Beste mensen,
Bij versie 3 maakte wij gebruik van een wfs request met een bounding box om alle percelen binnen dit gebied op te halen. Als we dan boven een stad zaten hadden we te maken met een limiet van 1000. Deze omzeilde we door met de startindex te spelen om zo meer resultaten op te halen.
Bij versie 4 werkt dit deels niet meer. Nu doet die meerdere requests terwijl we niet eens aan het limiet van duizend komen. Dit maakt alles traag.
De oude url zag er zo uit:
https://geodata.nationaalgeoregister.nl/kadastralekaartv3/wfs?request=GetFeature&version=2.0.0&startindex=" + requestLength + “&typename=kadastralekaartv3:perceel&srsname=EPSG:4326&outputFormat=application/json&bbox=” + bbox.replace(/\s/g, ‘’) + "
Hier lieten we zodra het limiet van duizend bereikt werd de startindex starten vanaf 1000 en zodra de 2000 bereikt werd vanaf de 2000 totdat we alle bijvoorbeeld 4325 of 6377 percelen opgehaald hadden binnen de bounding box.
De nieuwe url ziet er zo uit:
https://geodata.nationaalgeoregister.nl/kadastralekaart/wfs/v4_0?service=WFS&request=GetFeature&count=1000&version=2.0.0&startindex=" + requestLength + “&typename=kadastralekaartv4:perceel&srsname=EPSG:4326&outputFormat=application/json&bbox=” + bbox.replace(/\s/g, ‘’) +
Hier hebben we alle parameters veranderd naar versie 4 en we krijgen resultaten terug. Nu haalt die als er bijvoorbeeld in totaal 420 percelen zijn eerst 374 op en daarna nog eens 30 en daarna de overige paar percelen. Hij doet dus heel snel 3 requesten in plaats van bij elke 1000 zoals het was.
Weet iemand een manier hoe wij dit kunnen oplossen?
M.v.g.
Tim Maters
Beste Tim,
In principe is er niets verandert aan de wijze waarop de startindex werkt. Je kan deze - met andere woorden - nog steeds gebruiken om te pagineren (tot een startindex van 10.000). Het is niet mogelijk dat de WFS service de request meerdere keren doet. Dit wordt altijd vanuit de consumerende applicatie getriggerd. Zou je iets meer achtergrond kunnen geven over de wijze waarop je de WFS service gebruikt. Aan je voorbeeld te zien lijk je zelf iets ontwikkeld te hebben.
Beste hulstg,
de code die wij gemaakt hebben is als volg:
var requestLength = 0;
var nextstep = false;
function request() {
var previousRequestLength = requestLength;
if(nextstep = false) {
var bbox = getBbox(map);
$.getJSON("https://geodata.nationaalgeoregister.nl/kadastralekaart/wfs/v4_0?service=WFS&request=GetFeature&version=2.0.0&startindex=" + requestLength + "&typename=kadastralekaartv3:perceel&srsname=EPSG:4326&outputFormat=application/json&bbox=" + bbox.replace(/\s/g, '') + "", function( data ) {
console.log(data);
requestLength = requestLength + data.features.length;
if(previousRequestLength != requestLength) {
request() ;
requestData.push(data.features);
} else {
nextStep = true;
requestLength = 0;
request() ;
}
});
}
} else {
derest
}
Wat we hier dus doen is inderdaad zelf loopen todat we alle resultaten binnen hebben gehaald. Dit was bedoeld om het limiet van 1000 te omzeilen. Als de request function minder dan duizend percelen gaf ging die verder naar de volgende stap. Anders deed die nog een request om de volgende 1000 (of minder) op te halen.
Wat we nu het probleem is, is dat we niet elk perceel terug krijgen terwijl we de limiet niet eens bereikt hebben van 1000. Stel er zijn dus 480 percelen dan haalt die er eerst 460 op en dan 7 en dan 13 waardoor er dus meerdere requesten uitgevoerd worden door onze functie. Het lijkt er dus op alsof we bij het eerste request niet gelijk alle percelen binnenkrijgen waardoor onze functie de overige nog op gaat halen.
@TimMaters Zou je me de requesten kunnen sturen die worden gedaan, dus met de startindex en bbox ingevuld? Ik kan het namelijk niet reproduceren. Als ik nu een request doe krijg ik gewoon 1000 features terug als die in de bbox aanwezig zijn.
@hulstg Onze eerste request ziet er als volgt uit:
https://geodata.nationaalgeoregister.nl/kadastralekaart/wfs/v4_0?service=WFS&request=GetFeature&version=2.0.0&startindex=0&typename=kadastralekaartv3:perceel&srsname=EPSG:4326&outputFormat=application/json&bbox=160669,384999,162565,385691
Omdat we hier niet gelijk 1000 percelen terugkrijgen ziet onze tweede request er als volgt uit omdat we de lengte van de eerste features als requestlength zetten. We krijgen er 995 terug in plaats van 1000. Het ziet er als volgt uit:
https://geodata.nationaalgeoregister.nl/kadastralekaart/wfs/v4_0?service=WFS&request=GetFeature&version=2.0.0&startindex=995&typename=kadastralekaartv3:perceel&srsname=EPSG:4326&outputFormat=application/json&bbox=160669,384999,162565,385691
Vervolgens gebeurt dit nog eens namelijk:
https://geodata.nationaalgeoregister.nl/kadastralekaart/wfs/v4_0?service=WFS&request=GetFeature&version=2.0.0&startindex=1391&typename=kadastralekaartv3:perceel&srsname=EPSG:4326&outputFormat=application/json&bbox=160669,384999,162565,385691
En hierna nog een keer namelijk:
https://geodata.nationaalgeoregister.nl/kadastralekaart/wfs/v4_0?service=WFS&request=GetFeature&version=2.0.0&startindex=1396&typename=kadastralekaartv3:perceel&srsname=EPSG:4326&outputFormat=application/json&bbox=160669,384999,162565,385691
Zoals je kunt zien is bij elke request de bbox precies hetzelfde alleen lijkt het alsof we niet alle percelen gelijk kunnen ophalen (tot aan het limiet uiteraard).
Hoe het dus werkte was bij de eerste request 0-1000 features en vervolgens de overige 396 bij nog een tweede request.
@TimMaters Dit lijkt inderdaad een issue in de service te zijn. Ik heb er aan onze kant een ticket voor aangemaakt zodat we dit kunnen onderzoeken en oplossen.
1 like
@hulstg Hartstikke bedankt voor de tijd en moeite! Dan laten we het gewoon zo staan.
@TimMaters
Het probleem lijkt in combinatie met de BBOX query params en de srsname te zitten.
Indien je srsname=EPSG:28992 gebruikt gaat het goed, is dat een workaround die je tijdelijk zou kunnen gebruiken?
Beste Dennis,
Hetzelfde probleem lijkt zich ook voor te doen met “https://geodata.nationaalgeoregister.nl/bag/wfs/v1_1?request=GetFeature&service=WFS&version=2.0.0&typeName=bag:pand&BBOX=122664.0,486721.0,125164.0,489221.0&SRSNAME=EPSG:4326&outputFormat=json”
BBOX is een willekeurig voorbeeld boven 1000. Bij eerste request wordten geen 1000 maar 988
features opgehaald.
Eerdere versie van zelfde request werd gedaan bij "https://geodata.nationaalgeoregister.nl/bag/wfs?request=GetFeature&service=WFS&version=2.0.0& …
In ieder geval die api gaf ook totalFeatures terug. Ik ben er niet zeker van dar v1_1 dat ook heeft gedaan voor de wijziging. Ik vermoed van wel.
Groet Jan Winsemius
Beste Jan Winsemius,
Ja lijkt dezelfde oorzaak te hebben, als workaround zou je &SRSNAME=EPSG:28992 kunnen gebruiken. Weet dus niet of dat een optie is voor jou.
Met vriendelijke groet,
Dennis Rutjes
Ik had gezien dat dat een optie is, heb ik gedaan. Bedankt.
Overigens, hoort in v1_1 nu ook totalFeatures te worden teruggegeven of niet?
@DennisRutjes
Aangezien wij er op het moment nog geen haast bij hebben de komende maand/ 2 maanden denken wij nog niet aan een workaround. Zoals @hulstg al schreef zullen ze dit probleem oplossen. Wij wachten dit voorlopig af. als het langer gaat duren dan verwacht gaan wij kijken naar de workaround die u omschrijft.
@TimMaters we hebben de afgelopen dagen verder onderzoek gedaan en dit zojuist intern besproken. Er zitten nog wel best wel wat haken en ogen aan het issue dus we zouden toch de work-around willen adviseren. Excuses voor het ongemak!
@Jeroen_D Verwachten jullie wel dat het in de loop der tijd (komend half jaar) nog wordt opgelost of stellen jullie dit issue uit voor een volgende versie?
@TimMaters we moeten verder onderzoeken welke definitieve oplossing het beste is en welke impact dat heeft maar ik ga nu voor de zekerheid maar niet van komend half jaar.
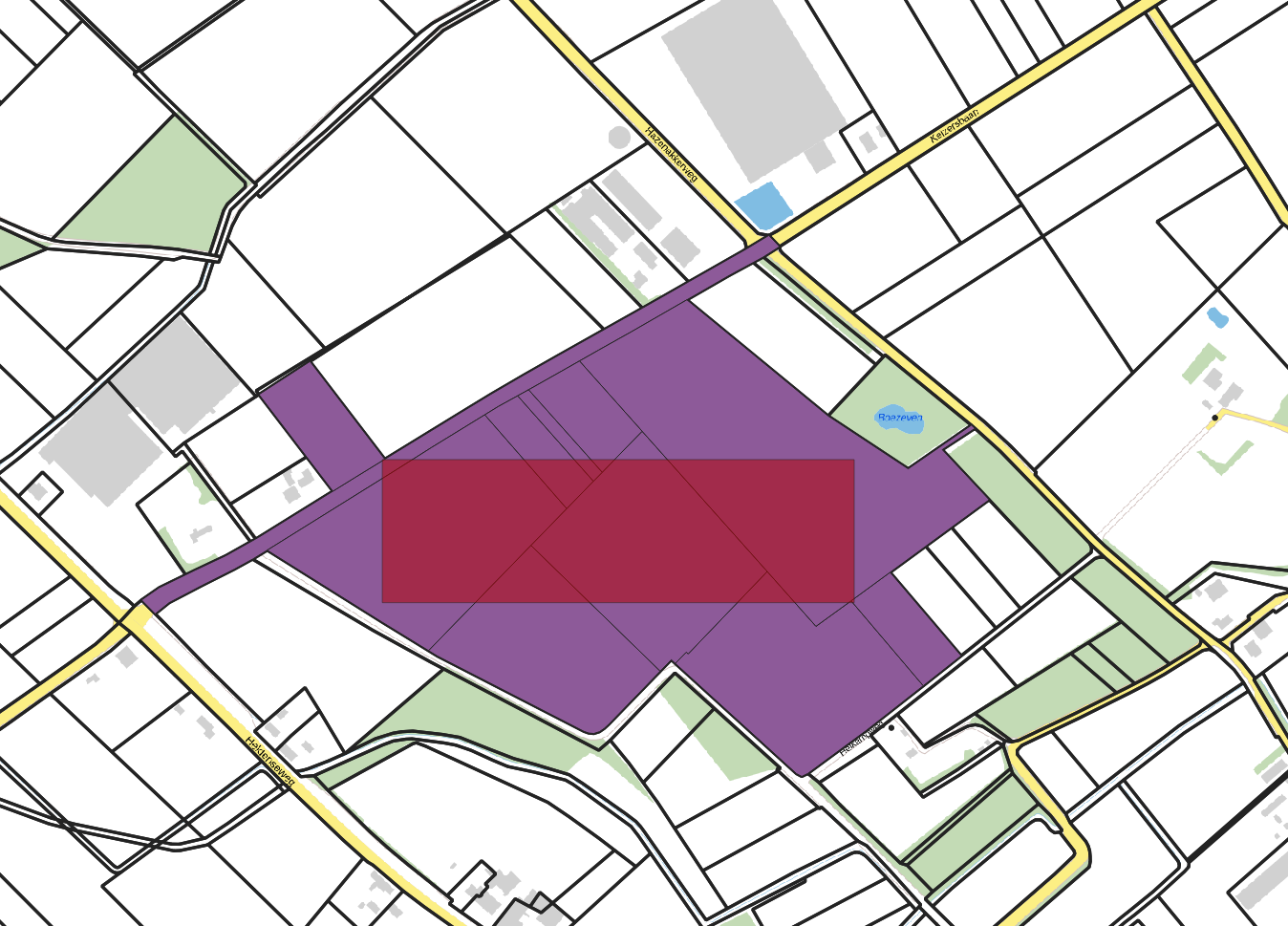
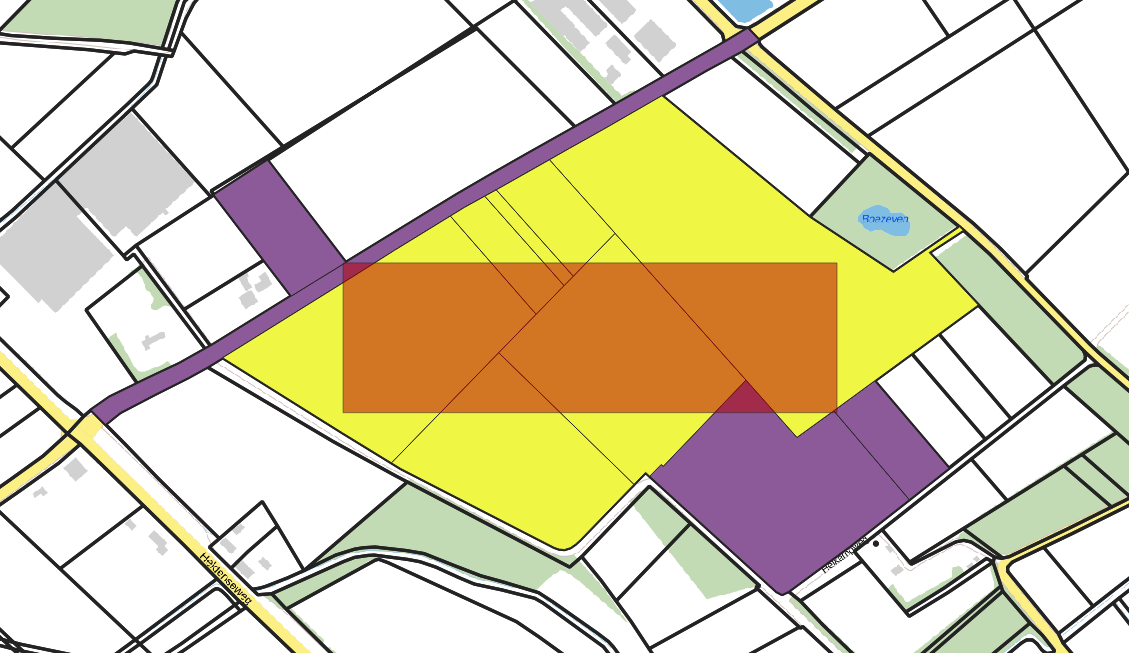
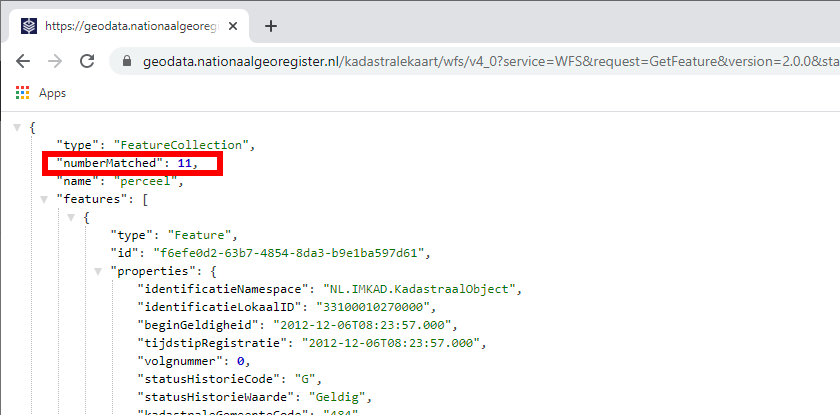
@DennisRutjes Die workaround levert het zelfde resultaat op alleen met andere coördinaten. Waar we nu ook achter gekomen zijn is dat de startindex functie niet nauwkeurig is. als we eerst de start index op 0 zetten krijgen wij 11 percelen terug met de request als volgt:
https://geodata.nationaalgeoregister.nl/kadastralekaart/wfs/v4_0?service=WFS&request=GetFeature&version=2.0.0&startindex=0&typename=kadastralekaartv3:perceel&srsname=EPSG:4326&outputFormat=application/json&bbox=200220,368182,200695,368326
Omdat die door het issue niet alle features in een keer ophaalt doen we deze request nog eens maar dan met startindex 11. We krijgen nu een aantal dubbele resultaten terug in plaats van dat de request de overige percelen ophaalt.
https://geodata.nationaalgeoregister.nl/kadastralekaart/wfs/v4_0?service=WFS&request=GetFeature&version=2.0.0&startindex=11&typename=kadastralekaartv3:perceel&srsname=EPSG:4326&outputFormat=application/json&bbox=200220,368182,200695,368326
Hebben jullie hier wel een oplossing voor?
Hoi @TimMaters,
Een vraagje waarom zijn jullie niet tevreden met die 11 percelen die jullie terugen  ?
?
Als ik ze visualiseer lijkt het allemaal te kloppen…
De opgegeven bbox zou ook maar 11 percelen moeten teruggeven.
Het tweede request waar jullie verder gaan geeft bij mij een ‘subset’ van de 11 eerste percelen terug…
Om eerlijk te zijn weet ik niet of dit ‘gewenst’ gedrag is m.b.t. de tweede call (gezien er dan dubbellingen ontstaan). Maar wat ik wel kan zeggen is dat het eerste request goed is qua response. Deze geeft 11 (de gewenste, neem ik aan) percelen terug met de melding dat er ook 11 matches waren. Dan is de vraag waarom jullie ‘verder zoeken’ als er 11 van de 11 terugkomen? Of zie ik iets over het hoofd?
Ik zou nu zeggen vooral niet verder zoeken
Hallo @wouter.visscher,
Zoals we in het begin van dit topic al melde deden we bij de vorige versie eerst 1000 features ophalen en stond de startindex in het begin op “0”. Vervolgens wisten we dat we aan het limiet zaten en haalde we de eerst volgende features vanaf de startindex “1000” op om zo alle percelen te verkrijgen. Volgens uw collega’s werkt dit bij de nieuwe versie niet meer.
Onder de duizend features deden we dit bij de oude versie ook. We begonnen dan met een request waar de startindex “0” was en kregen er vervolgens bijvoorbeeld 11 terug. De eerst volgende request had dan een startindex van “11” alleen kregen we nu geen percelen meer terug. Hierdoor wisten we dat we alle percelen in de boundingbox hadden en gingen we verder naar andere code.
Bij de huidige versie doet die dus eerst 11 percelen ophalen en vervolgens niet 0 maar nog eens een aantal die ook nog eens dubbel zijn met elk een van de 11 percelen zoals we ook in jouw voorbeeld zien.
Nu kunnen we dit onder de limieten inderdaad makkelijk oplossen door het te houden bij 1 request alleen zo weten we boven een drukke stad niet of we alle percelen hebben omdat de request limiet is bereikt. Zo ontstaat er boven bijvoorbeeld Eindhoven of Amsterdam een gatenkaas aan percelen.
Heeft u hier een oplossing voor? Hoe verkrijgen we bijvoorbeeld 5000 percelen zonder dat er dubbele inzitten?
Hoi @TimMaters
Misschien nog eerst een andere vraag vanuit mijn (ons, PDOK): Waarom maken jullie, gezien de hoeveelheid data die je naar binnen wil trekken, geen gebruik van de BRK download api
https://downloads.pdok.nl/kadastralekaart/viewer/
1 like
@wouter.visscher is deze data real-time? We willen onze kaart up-to-date houden en als ik het goed begrijp is de BRK download api dat niet aangezien je alle data moet downloaden en lokaal op de server zet.
Zie ik dit goed?