De data is net zo up-to-date als de WFS
dat doen jullie nu ook…
Misschien goed om te delen, wat voor applicatie jullie hebben?
De data is net zo up-to-date als de WFS
dat doen jullie nu ook…
Misschien goed om te delen, wat voor applicatie jullie hebben?
Hoi @wouter.visscher,
Oke dan gaan wij hier eens naar kijken. Bedankt voor het antwoord!
M.v.g.
Tim Maters
Beste @wouter.visscher,
Ik denk dat het inderdaad goed is om een betere uitleg over onze applicatie te geven.
Wij zijn bezig met een applicatie waarin we gebruik maken van Google Maps. Wij willen met behulp van de kadastrale kaart v4 percelen op google Maps zetten doormiddel van de coördinaten die we bij jullie ophalen. Google Maps heeft een functie om polygons te tekenen als er een “path” gezet wordt met de coördinaten.
Wanneer de klanten klikken op een perceelgrens (Google Maps polygon) kunnen ze het perceel toevoegen in onze database. Vervolgens wordt de perceel data binnen onze applicatie nog aangevuld met andere data van de klant zelf. Wanneer de klanten weer naar de kaart gaan kunnen ze ook op een perceel klikken om de reeds ingevoerde data in te zien. Hierbij kijken wij of er een match is in onze database aan de hand van de gemeente code, sectie, en perceelnummer en vullen we de gegevens aan…
Omdat onze applicatie straks door verschillende mensen in heel Nederland gebruikt gaat worden is er niet een specifiek gebied waarvan wij de feature data nodig hebben maar altijd verschillend.
Wanneer klanten ons systeem gebruiken gaan ze naar de kaart en zien ze het eerst volgende scherm:
Alle polygons die je hierboven ziet is data van ons zelf die we met behulp van de google maps polygon functie getekend hebben. Zodra klanten inzoomen naar een bepaald zoomlevel zien ze het volgende:
Dit is het eerste zoomlevel waarop wij de kadastrale kaart laten zien met jullie data namelijk de percelen (de zwarte lijnen). Wij halen deze data op doormiddel van een eerder genoemd wfs request. Omdat we in het request de google maps bounding box zetten waarop de klant zich dan bevindt krijgen we alle percelen die daarbij horen. Elke keer als een klant met zijn muis de kaart versleept wijzigt de bounding box en doen we een request om de bijbehorende percelen op te halen. Zoomt een klant in dan doen we dit ook alleen wordt de request kleiner omdat de bounding box ook kleiner wordt.
Boven een gebied met veel grote weilanden zal de request een laag aantal features terug geven maar zodra de klanten boven een random stad komen zal dit boven het limiet uitkomen. Wij hadden dit bij de vorige versies opgelost met behulp van de startindex. Dus bij 2500 features deden we 3 requests. Zo kregen de klanten alle percelen te zien die in deze stad lagen en niet maar 1000. Nu werken we op dezelfde wijze maar zijn de aantallen features per request variabel, dus niet telkens 1000, en bevat het uiteindelijke resultaat dubbele percelen.
Omdat wij dus niet weten waar de klant de percelen op wilt halen hebben wij ook geen vaste bounding box maar een random bounding box afhankelijk van waar google maps zich bevindt. Als we alle data moeten downloaden houdt dit in dat we meer dan een miljoen features hebben op onze server die we elke dag opnieuw moeten downloaden omdat het anders niet up-to-date is.
Je zegt dat we nu ook al downloaden maar dat is dus niet het geval. Wij maken een request en met de coördinaten die we krijgen vanuit het kadaster tekenen we met de Google Maps polygon functie de polygons (perceelgrenzen) en vullen dit aan met reeds ingevulde klantgegevens.
Hoi @TimMaters
Als ik het goed begrijp halen jullie duizenden percelen op (via de WFS) terwijl de klant er 1 (of i.i.g. een klein aantal!?) selecteert die dan weggeschreven wordt naar jullie backend (+ dan verrijkt met additionele informatie).
Persoonlijk zou ik dit proberen op te lossen door een combinatie van een WMS en een WFS te gebruiken (i.p.v. alleen een WFS). Dus de WMS om alles te visualiseren (er vanuit gaande dat jullie libs gebruiken die WMS ondersteunen, schijnbaar iets als een: “Google Maps ImageMapType” ) zoals:
https://geodata.nationaalgeoregister.nl/kadastralekaart/wms/v4_0?SERVICE=WMS&VERSION=1.3.0&REQUEST=GetMap&FORMAT=image%2Fpng&TRANSPARENT=true&layers=Perceel&CRS=EPSG%3A28992&STYLES=&WIDTH=2272&HEIGHT=1794&BBOX=202430.76%2C369572.27999999997%2C203385%2C370325.75999999995 (en dan natuurlijk in de juiste PROJ enz…)
En dan door middel van een WFS GetFeature request ‘prikken’ in de WFS laag om de juiste polygoon (geometry) van een perceel te importeren in jullie applicatie (als een Google Maps polygon) en dan weg te schrijven naar een DB. Dan zitten jullie niet met het probleem van het continue importeren van vectordata waarvan 99,99% niet gebruikt gaat worden door een klant.
Wanneer ik je uitleg lees krijg ik het gevoel dat jullie view service functionaliteit aan het bouwen zijn op een download service. Voor deze functionaliteiten is het meestal praktischer(/gebruikelijker) omdat met een WMS service te doen. Welke geoptimaliseerd is voor het visualiseren (je krijgt namelijk een kant-en-klaar plaatje terug die je direct op je kaart kan “gooien”).
Hoi @wouter.visscher,
De reden dat wij niet voor een WMS request gekozen hebben is omdat wij hierbij niet voor elk perceel kunnen bepalen hoe die er uit komt te zien. Als onze klanten percelen in onze database toegevoegd hebben koppelen wij later een bepaalde status aan elk perceel. Aan de hand van die status krijgt elk perceel een aparte kleur.
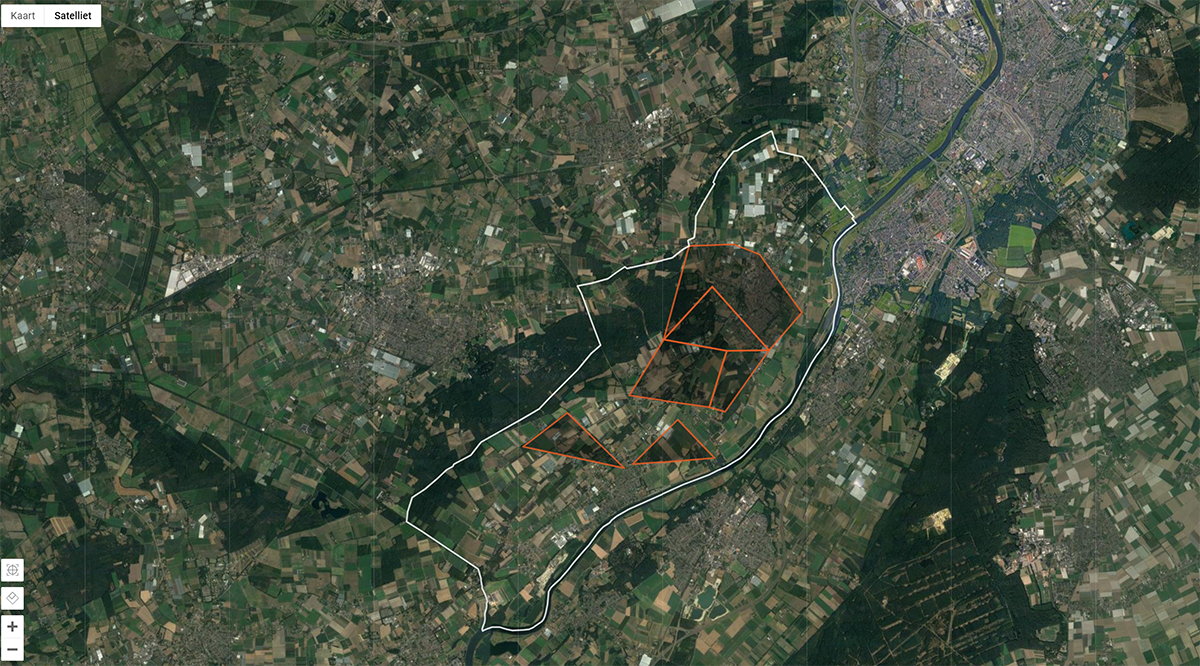
In het volgende plaatje zie je wat we bedoelen:
De klant kan in dit scherm alle percelen binnen de oranje lijn toevoegen. De kleuren zetten we door de WFS request: gemeentecode, sectie en perceelnummer te vergelijken met onze eigen data. Vervolgens als we alle matches gevonden hebben tekenen we alle polygons.
De reden dat we niet na het toevoegen ook de perceel coördinaten opslaan in onze database is omdat we anders elke nacht miljoenen percelen in onze database moeten bijwerken om de data up-to-date te houden.
Dus met andere woorden geeft een WMS request ons te weinig controle. Het percentage wat je noemt klopt dus ook niet. We gebruiken eerder 80% vectordata wel en 20% is wat buiten de klant zijn bevoegdheidsgebied ligt (buiten de oranje lijn grens).
“the plot thickens”
Voor deze use-case is dus precies de BRK download api in “het leven geroepen”. Waarbij de afnemer 1x een FULL download (van alle miljoen percelen, de ‘actuele stand’) waarna je daarna dagelijks (dezelfde update frequentie als de WFS, technisch gezien zelfs “iets” eerder up-to-date) de gemuteerde percelen naar binnen kan trekken en je database te updaten. M.a.w. je hoeft niet continue alle “miljoenen” percelen naar binnen te trekken. En als jullie ‘werken’ met bekende gebieden (de oranje polygonen) zou je op dat niveau ook de specifieke percelen (en indien aanwezig de mutaties) naar binnen kunnen halen.
Kijk voor jullie styling-probleem/issue is het idee om vanuit PDOK(/Kadaster) dit te gaan faciliteren d.m.v. Vector Tiles. Maar tot die tijd hebben we ‘helaas’ alleen de bestaande smaakjes (WMS/WFS/Download API).
Feit blijft dat wat jullie met de WFS proberen te doen “suboptimaal” gebruik daarvan is. Een WFS is geen bulkdownload interface, hoewel andere daar misschien anders overdenken is dit wel ons (PDOK) standpunt. En ik neem aan dat jullie dit enigszins kunnen beamen gezien er bewust’ om limieten heen wordt gewerkt.
Ik weet verder niet wat jullie capabilities/resources/ander functional requirements/enz… zijn, maar met deze ‘nieuwe’ informatie zou ik toch adviseren (zolang we nog geen VT van percelen hebben) dit met een DB + download API server-side op te lossen, al is het alleen maar om grip te krijgen op dit issue (c.q. het binnen jullie eigen invloedssfeer te trekken).
Beste Wouter,
Er zit toch wel wat in, wat Tim aankaart. Er zijn in de loop van de tijd verschillende topics geweest over die 1000 limiet en paginering, zowel bij brk asl bij bag. De essentie is denk ik niet in de eerste plaats of je de api nu overbelast met een oneigenlijke aanpak. Ik doe iets vergelijkbaars als Tim, maar dan zeer incidenteel . Alleen de eerste keer als je een gebied selecteert haal je soms meer dan 1000 features op. Die worden in de database bewaard. Dat is zo incidenteel dat een volledige download overkill is van Nederland overkill is.
De essentie is dat de specificatie zegt dat je tot 10.000 per 1000 kan pagineren.
Als je op die manier 1500 features ophaalt is het nog niet zo erg dat er dubbelen in zitten. Filteren is niet zo ingewikkeld. Het probleem is groter als er features missen. Dan werkt de paginering feitelijk niet lijkt mij.
Op een gegeven moment was op het forum gegeven “oplossing” om als bounding box epsg:28992 te gebruiken. Dat werkte inderdaad. Inmiddels vallen er ook bij epsg:288992 gaten.
Voor mij zou de vraag dus primair zijn of paginering tot 10.000 nog ondersteund wordt. Als er dubbelen en gaten in vallen is dat niet het geval lijkt me, of mis ik hier iets essentieels?
Ik ben benieuwd.
Groet Jan
Mee eens, anders zouden we de discussie ook niet aangaan.
Heb je een voorbeeld (aantal requesten waarmee we dit kunnen reproduceren?)
De paginering tot 10.000 was/is een max om het ‘gedrag’ van harvesting tegen te gaan, niet zo zeer dat er 10.000 features naar binnen mogen worden getrokken.
Dat er gaten of overlap ontstaat bij dergelijke requesten in de +1000 features vind ik (dit is iets persoonlijk) minder ‘erg’ gezien we voor dit hoeveelheid data anders alternatieven hebben (zoals de download API).
Mocht dit ook het geval zijn bij ‘kleinere’ hoeveelheden features dan is dat zeker iets wat bij ons op de backlog zou moeten komen om uitgezocht te worden.
Mogelijk ontstaan dubbelingen en gaten in de respons omdat er meerdere backends worden gebruikt. Dit is te ondervangen door op een bepaald attribuut te gaan sorteren. Dit kan in de WFS d.m.v. de SORTBY-parameter. Zie ook hier: ResultPaging bij WFS datasets - #2 door wouter.visscher - Standaarden - Geoforum
Wouter, dank voor je reactie.
Laat ik vooropstellen dat ik niet steeds over de 1000 ga, laat staan richting 10.000.
Ik haal in principe percelen en bebouwing op voor plekken waar iemand plannen aan het maken is.
Meestal zit dat onder de 300 en het ophalen is steeds incidenteel.
Soms in stedelijk gebied schiet iemand er overheen. Dan zit je ergens tussen de 1000 en 2000. Dat is incidenteel en eigenlijk niet voldoende om de download faciliteit te gebruiken.
Bovendien, die download is er toch alleen voor kadaster percelen en niet voor bag panden?
Het ging mij er vooral om wat je kan verwachten. Als je bij pagineren iets gaat missen vind ik dat ook niet erg als ik het weet! Dan ga je namelijk wat anders doen. Ik zou bij api beschrijving aangeven dat je bj pagineren boven 1000 niet altijd compleet bent.
Nu was het een verassing in het weekend, wat natuurlijk altijd irritant is ;-). Vooral vreemd omdat het eerst wel werkte.
Request heb ik inmiddels eruit gegooid, omdat ik wat anders doe, maar was het ging in ieder geval mis bij een request op
Exacte bbox weet ik niet meer, maar was groter en leidde tot request van iets van 1400 features.
Antwoord van fsteggink moet ik even proberen. Dan heb ik weer wat geleerd vandaag!! Dat is natuurlijk altijd mooi.
Dat ga ik proberen!
dank
Dit topic is 180 dagen na het laatste antwoord automatisch gesloten. Nieuwe antwoorden zijn niet meer toegestaan.