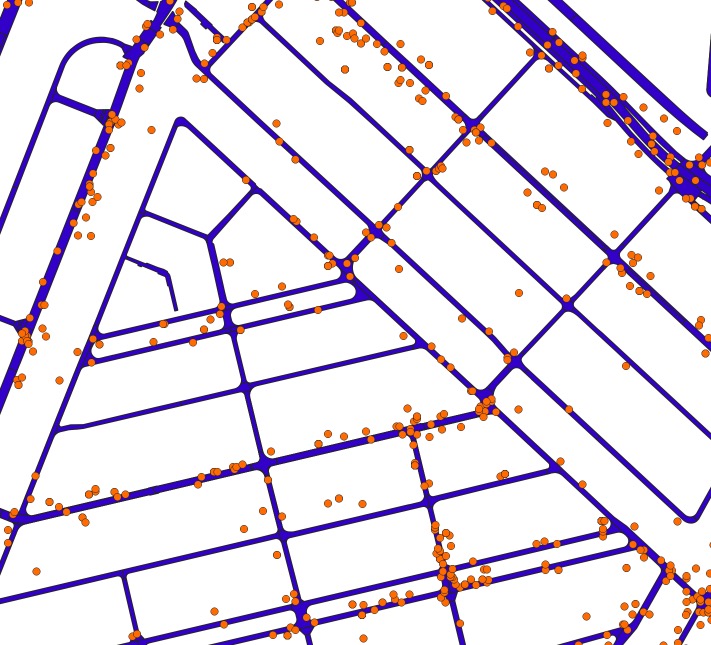
Ik heb een vector dataset met GPS locaties van verschillende voertuigen en een polygon wegennetwerk dataset. Vanwege de onnauwkeurigheid van de GPS-gegevens, kunnen deze GPS locaties tot 20 meter afwijken van het wegennetwerk. Om iets te kunnen zeggen over de kwaliteit van de GPS dataset zou ik graag de nauwkeurigheid van de GPS-metingen in relatie tot het wegennetwerk willen berekenen.
Zelf zat ik te denken om de afstand van elk GPS punt tot het dichtstbijzijnde wegsegment te berekenen en vervolgens het gemiddelde te nemen om uiteindelijk de gemiddelde ruimtelijke variatie van alle GPS punten tot het wegennetwerk te verkrijgen. Is dit de beste manier om de nauwkeurigheid van m’n GPS-metingen te berekenen, of raadt iemand wat een andere methode aan om dit te berekenen in QGIS?
Een aandachtspunt bij deze aanpak is dat op sommige plekken de ligging van een wegsegment in het wegenbestand ook niet helemaal zal kloppen. Daardoor zal je inschatting van de nauwkeurigheid van de GPS-metingen te pessimistisch zijn.
Daarnaast lijkt het me beter om niet de gemiddelde afwijking (mean error) berekenen maar de “standaardafwijking” (RMSE, root mean square error). Dat is een gebruikelijker maat voor precisie.
Om te voorkomen dat enkele GPS-punten met een erg grote afwijking (outliers) de uitkomst van je analyse overheersen, zul je dergelijke punten er uit moeten filteren. Dat kan handmatig of met een iteratief proces. Een idee voor iteratieve filtering van outliers:
Bereken de RMSE;
Verwijder alle GPS-punten met een afwijking groter dan 3 keer de RMSE;
Ga naar stap 1 en herhaal totdat er geen punten meer verwijderd hoeven worden.
Dank voor je antwoord. Ik heb inmiddels de RMSE voor alle GPS-punten berekend (19.81) en zie dat er inderdaad veel GPS-punten tussen zitten met een erg grote afwijking (sommige met een afstand van +300 meter tot het dichtstbijzijnde wegsegment). Ik ben me er van bewust dat python geschikt is om stap 3 uit te voeren. Maar gezien het feit dat m’n python kennis zeer basaal is, vroeg ik me af of er een andere handige manier is om in QGIS alle GPS-punten met een afwijking groter dan 3 keer de RMSE te verwijderen en te blijven herhalen totdat er geen punten meer verwijderd hoeven te worden.
Je zou ook handmatig de punten die meer dat 3 keer de RMSE afwijken kunnen deleten en de RMSE herberekenen. Het aantal keer dat je deze handelingen moet herhalen zou beperkt moeten zijn. Als er eindeloos nieuwe punten boven de 3 keer de RMSE blijken te zijn, dan zou er wat mis met je data zijn.
Voor die 3 kan je ook een iets andere waarde gebruiken. Het idee er achter is dat je er van uit kan gaan dat de afwijkingen bij benadering een spreiding hebben volgens de normale (gaussische) verdeling. De kans op een afwijking van meer dan 3 keer de standaardafwijking (sigma) is dan 1 - 0,997 = 0,3%. Voor dergelijke punten is het dus aannemelijk dat ze niet bij de normale verdeling van de GPS-metingen horen en daarom wil je ze niet gebruiken voor het bepalen van de RMSE. Wel zou je het percentage van dit soort outliers naast de RMSE kunnen vermelden als kwaliteitsindicator.
De statistisch nette manier is om een waarde i.p.v. 3 te kiezen op basis van een afweging tussen de kans op een fout van de eerste soort en een fout van de tweede soort (false positives en false negatives). Dan komt men meestal ergens tussen 2 sigma (95%) en 3 sigma (99,7%) uit. Vervolgens hoor je strikt gesproken steeds maar 1 outlier (de grootste) te verwijderen. Om toch meerdere outliers tegelijk te verwijderen wil je liever aan de veilige kant blijven. Vandaar dat ik 3 voorstelde. Als je data netjes normaal verdeeld is met wat outliers, dan zou het niet zo veel uit moeten maken welke waarde je precies gebruikt.
Pas op dat je niet te veel punten verwijdert, anders hou je alleen de GPS-punten met vrij zicht op de hemel en dus goede ontvangst van satellieten over, wat een RMSE van ca. 2,5 meter zou moeten geven. Dat zou dan alleen niet representatief zijn voor de fout in gebieden met bebouwing en/of bomen.
Denk eraan dat de GPS niet alleen zijdelings afwijkt, maar ook langs de weg zelf. In jouw analyse mis je deze afwijking, De daadwerkelijke afwijking zal dus groter zijn dan die je berekent.
Dank voor je verhelderende uitleg. Op het moment heb ik de afstand voor elke GPS-meting tot het dichtsbijliggende wegsegment berekend met de Join attributes by nearest tool in QGIS. Daarbij heb ik de GPS-punten als input layer gebruikt en de wegdelen als input layer 2. De output layer bevat dan een ‘distance’ veld waarin de afstand in meters tot het dichtstbijliggende wegsegment is vermeld.
Vervolgens heb ik met een Field calculator de RMSE berekend met de volgende formule “SQRT((SUM(distance^2))/count(fid))”. Die was voor alle GPS-metingen 19.332. Met behulp van Extract by expression heb ik vervolgens alle features genomen die een waarde lager dan 3 keer de RMSE hebben “distance < (RMSE * 3)”. Vervolgens heb ik meerdere malen hetzelfde proces herhaald waarbij de RMSE van 19.332 achtereenvolgens daalde naar 6.141, 2.708, 1.421, 0.832. Dit proces lijkt voor mij dus niet te werken. Ook gezien @marco_duiker’s opmerking begin ik me steeds meer af te vragen of ik wel iets nuttigs kan zeggen over de nauwkeurigheid van m’n GPS data. Enige suggesties?
Ik zou graag de nauwkeurigheid (en daarmee de bruikkaarheid) van m’n GPS measurements willen proberen te duiden. De GPS metingen beslaan een groot stedelijk gebied, waarbij de GSP-metingen in hoogstedelijk gebied een stuk minder nauwkeurig zijn dan de GPS-metingen in meer open gebieden buiten de stad.
Daarnaast had ik het idee om met de uiteindelijk afwijking in meters tot het dichtstbijliggende weggedeelte, de breedte van geofences te bepalen die ik zou willen creeren op bepaalde wegdelen. Uiteindelijk wil ik analyseren hoe vaak bepaalde GPS punten (gecategoriseerd op car_id) in een bepaalde geofence zijn geweest. Is dat realistisch gedacht?
En als je in plaats van 3 een grotere drempelwaarde gebruikt (4 of 5 keer RMSE)? Convergeer je dan wel naar een waarde, of blijft de RMSE dan ook alsmaar kleiner worden? Als de RMSE echt niet wil convergeren, dan betekent dat dat je data geen normale (gaussische) verdeling heeft. In dat geval is de RMSE sowieso niet zo’n geschikte maat en kan je misschien beter een histogram van de afwijkingen maken.
Tenzij je verwacht dat door de locatie van de antenne op het voertuig de fout in de rijrichting heel anders is dan de fout haaks daarop, dan is het punt van Marco Duiker dat je de 1D afwijkingen meet geen onoverkomelijk probleem. Je zou dan de gevonden waarde gewoon met wortel 2 kunnen vermenigvuldigen om de 2D afwijking te krijgen.
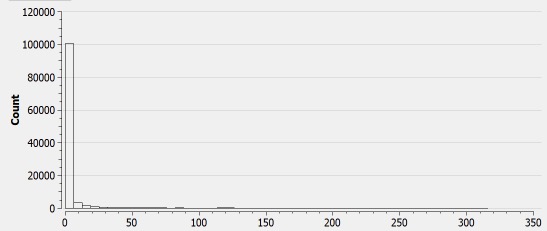
Een grotere drempelwaarde zou denk ik niet uitmaken aangezien m’n data inderdaad geen normale (gaussiche) verdeling heeft, zie afbeelding hieronder waarbij de x-as aangeeft hoeveel meter de GPS-punten van het dichtstbijliggende wegsegment liggen
Het lijkt me een wat voorbarige conclusie dat je data niet normaal verdeeld is. Daarvoor zou je een histogram met kleinere intervallen (bijv. 1 m), dus met veel meer staafjes, moeten maken.
Bruikbaarheid hangt altijd samen met een doel. Het een kun je niet beoordelen zonder het ander. Wellicht is voor een bepaald doel de nauwkeurigheid van je bepaling van de nauwkeurigheid voldoende.
Da’s makkelijk, 1 of minder. Een punt is erin of eruit. Maar wellicht wil je kijken hoe vaak een auto binnen of buiten de geofence is geweest? En wat bedoel je met hoe vaak? Het aantal hangt af van de frequentie waarop de GPS punten wegschrijft. Wil je dit dan percentagegewijs?
De GPS metingen worden elke 10 seconden gegenereerd. Samen construeren deze punten een afgelegd traject. Ik zou graag willen analyseren hoe vaak zo’n traject een geofence (die over een bepaald wegsegment ligt) doorkruist. Daarvoor gebruik ik de GPS-punten en categoriseer ik die op car_id. Vanwege de onnauwkeurigheid van de GPS data tov het wegdek waar ze eigenlijk horen te liggen, wil ik graag de geofences een bepaalde breedte geven. Echter, hoe breder de geofence, hoe groter de kans dat een GPS-punt binnen zo’n geofence wordt geregistreerd. Als de geofence te breed is, kunnen GPS-metingen die eigenlijk tot een ander wegdeel behoren, onjuist worden geregistreerd als trigger. Daarom is het van belang de breedte van de geofence goed te overwegen. Ik dacht dat als ik de gemiddelde afstand van de GPS-punten tot het dichtstbijliggende wegsegment weet, ik die waarde zou kunnen gebruiken om de breedte van m’n geofences te gebruiken.
Voor de breedte van je geofence zul je een afweging moeten maken tussen wat je acceptabel vindt voor de fout van de eerste soort (de kans dat je onterecht denkt dat iemand binnen een geofence was) en de fout van de tweede soort (de kans dat je onterecht denkt dat iemand buiten een geofence was). Het histogram kan hierbij helpen omdat je daarin kan zien hoe vaak een fout van de tweede soort op treedt bij een bepaalde breedte van de geofence (de som van alle staafjes rechts van die breedte).
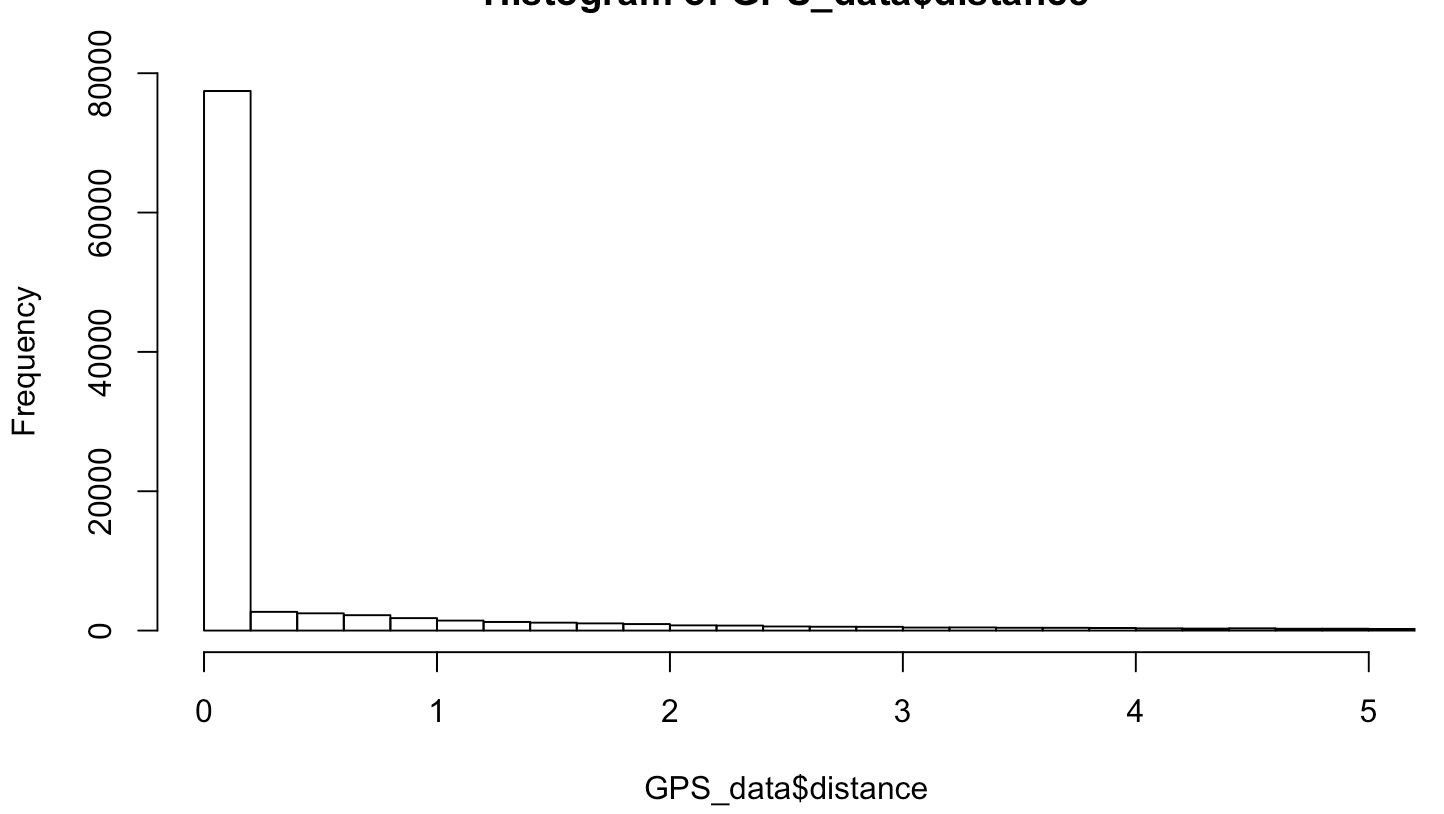
Door de enorme staaf bij 0 meter is er echter niet zo veel te zien in de twee histogrammen die je gemaakt hebt. De interessantste informatie zou in het stuk van 1 tot max. 50 meter moeten zitten.
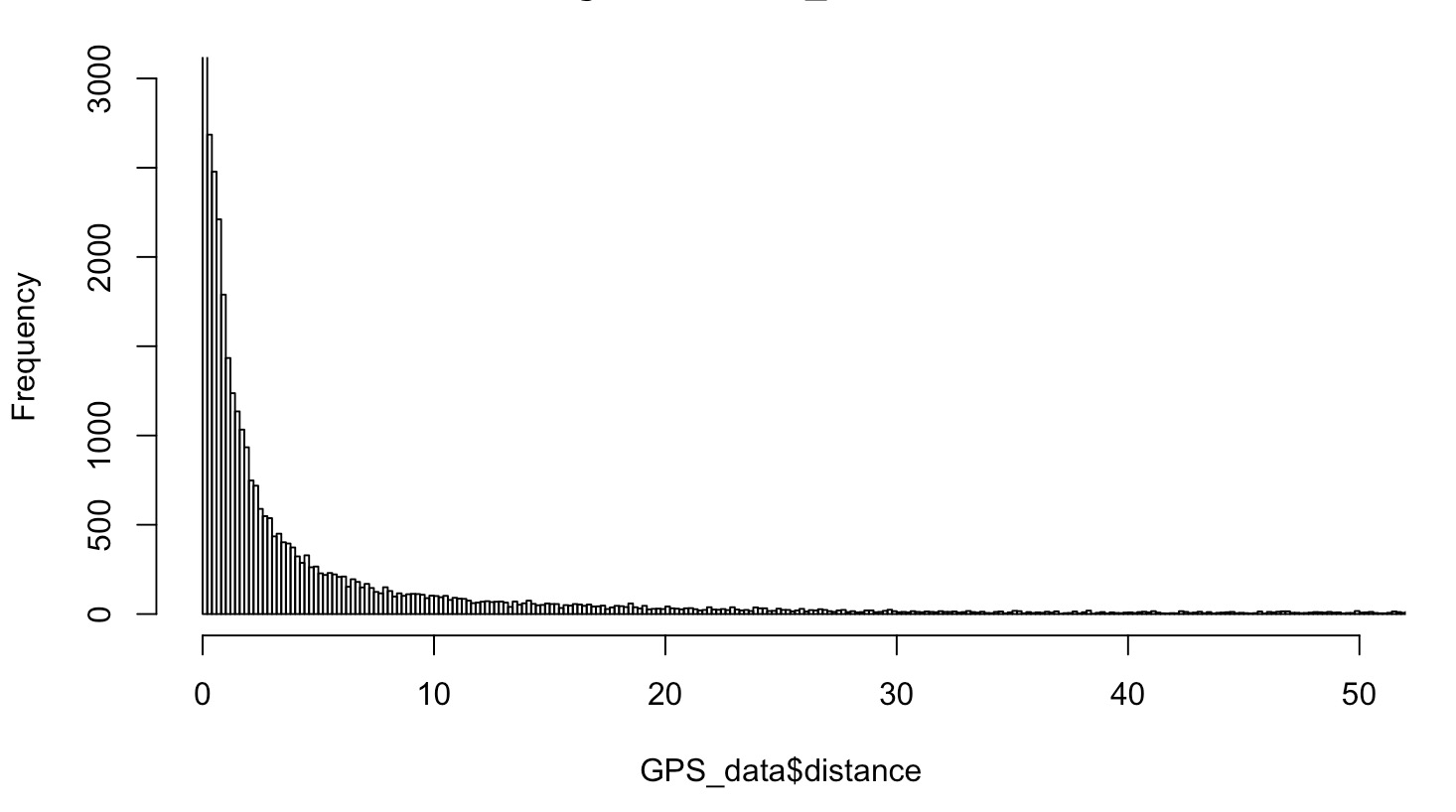
Ik heb de histogram nog eens gemaakt en dit keer ingezoomed (y-as waarde op maximaal 3000 gezet). Als ik er dus voor kies om de breedte van de geofence op 5 meter in te stellen (dwz 5 meter aan de linkerkant van de weg en 5 meter rechts van de weg, uiteindelijke breedte dus 10 meter), hoef ik simpelweg het percentage te tellen van alle GPS punten die een waarde gelijk of groter dan 5m hebben? Als ik dat doe kom ik uit op 10,51%. Wanneer ik de geofence breedte aan beide kanten op 10 meter zou zetten, kom ik uit op 7,10%. Hoe bepaal ik uiteindelijk wat ik acceptabel vind voor de fout van de tweede soort? Ik moet er overigens bij vermelden dat de histogram hieronder van de oorspronkelijke data is, eventuele outliers zijn hierbij nog niet uitgefilterd volgens de manier die je voorstelde omdat nog niet duidelijk was of de data normaal verdeeld is. Maar dat lijkt wel het geval te zijn?
De verdeling lijkt niet echt de klokvorm van de normale verdeling te hebben maar meer de dubbele asymptoot van y=1/x. Dat verklaart wellicht waarom het filteren niet werkte. Dat uitfilteren is vooral nodig als je een standaardafwijking of RMSE zou willen berekenen. Als je de breedte van de geofence bepaalt op basis van de fout van de tweede soort door de percentages uit het histogram op te tellen dan is filteren niet nodig. Wat acceptabel is voor de fout van de tweede soort is aan jou om te bepalen op basis van wat is de schade van een fout van de tweede soort is.
Oke dus met de huidige verdeling van m’n data raad je dus af om een standaardafwijking of RMSE te berekenen omdat het filteren uiteindelijk niet werkt.
Van de twee soorten fouten die je in vorige reactie schetste, wil ik het liefst de fout van de eerste soort voorkomen (de kans dat er onterecht wordt gedacht dat iemand binnen een geofence was). Dat zou de uitkomst van de analyse teveel en onjuist kunnen beinvloeden. Ik maak in dat geval de breedte van geofences liever wat kleiner waardoor de kans op de eerste fout afneemt, maar de kans op de tweede fout snel toeneemt. De toegenomen kans op de fout van de tweede soort moet ik in dat geval maar toeschrijven aan de onnauwkeurigheid van de GPS data, en in dat geval werken met een kleiner aantal GPS-metingen. Als ik dus besluit om de geofence op 5 meter aan beide kanten van het wegdek in te stellen, dan kan ik dus stellen dat ik 10,51% van m’n GPS punten als outliers classificeer en 89,49% van m’n GPS metingen meeneem voor m’n uiteindelijke analyse? Ik moet neem ik aan zelf beslissen of ik dat voldoende vind om mee te werken, maar dat lijkt me een redelijk arbitraire beslissing. Is er niet een andere methode mogelijk die mij hierin enigszins zou kunnen leiden?